|
|

About AMP Lab Projects Downloads Publications People Links
Project - All Focused Light Field Rendering by Fusion

· Approach
· Results
· Contact
|
Akira Kubota |
|
Motivation and Goal |
In
contrast to traditional geometry based methods, image based rendering (IBR)
methods can render a novel view of a scene using a set of pre-acquired images
without requiring geometry. However, IBR method requires a large number of
images captured with densely arranged cameras (i.e., high sampling density of
light field on the camera plane) for rendering a novel view with sufficient
quality. If the sampling density is low, the rendered view suffers from
aliasing artifacts such as blur and ghost.
In this
project, we propose a novel IBR method that enables us to render a novel view
with sufficient quality using less number of images compared with that required
for non-aliased rendering. Our method is not based on pixel selection or depth
estimation. We model the multiple views in a novel form and create all in-focus
view by globally performing iterative filtering operations on the multiple
views.
Our
approach consists of two steps:
(1)
Rendering multiple views at a given view
point using light field rendering (LFR) with different focal plane depths.
(2)
Iterative reconstruction of all in-focus
view (a non-aliased view) by fusing the multiple views generated in the step
(1).
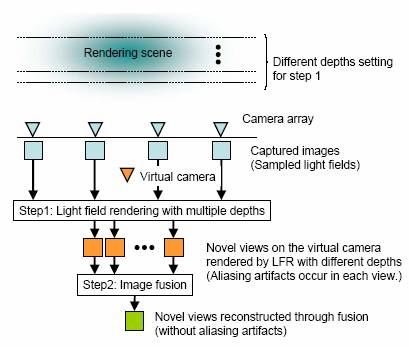
The step
(2) of our approach can reconstruct an all in-focus view directly from the
multiple interpolated views without depth map estimation. We model aliasing
artifacts as spatially varying filters and the multiple rendered views as a set
of linear equations with a combination of textures at the focal depths. We can
solve this set of linear equations for the textures by using an iterative
reconstruction method and obtain the desired all in-focus view as the sum of
the solved textures. This method effectively integrates the focused regions in
each view into an all in-focus view with less error. Note that this method does
not use any local processing steps such as feature matching, image segmentation
and depth estimation.
We used 81 real images captured with a 9x9 camera
array, which are provided from “The Multiview Image Database,” courtesy of the
University of Tsukuba, Japan. Image resolution is 480x360 pixels and the
distance between cameras is 20 [mm]. The scene contains an object (a doll) in
the depth range of 590-800 [mm], which is the target depth range in this
experiment. In this experimental condition, the distance between cameras is sparser
by about 5 times than that required for non-aliased rendering.

Figure (a) shows the novel views reconstructed by
the conventional LFR with the corresponding optimal depth at 5 different view
points. In Figure (a), the face of the doll appears in focus, while other
regions far from the face appear blurry or ghosted. The conventional LFR
algorithm cannot reconstruct all in-focus views at this sampling density. The
novel views reconstructed by the proposed method at the same view points are
shown in Figure (b). It can be seen that all the regions of the object are
reconstructed in focus without visible artifacts. In this reconstruction, we
set five focal planes at different depths, and render the novel views using LFR
at those depths. Examples of the views are shown in Figure (c), from which the
final view at the bottom of Figure (b) is reconstructed. From the top to the
bottom in Figure (c), the focal depth is changed from near to far. Although
many artifacts occur in the regions that are not in-focus, most of those
artifacts cannot be observed in the final views in Figure (b).
 The “Doll” scene (851 KB
QuickTime MPEG-4 format)
The “Doll” scene (851 KB
QuickTime MPEG-4 format)
|
Publications |
- A. Kubota, K. Aizawa and T. Chen, "Virtual view synthesis through linear processing without geometry," IEEE International Conference on Image Processing 2004, Suntec City, Singapore, Oct., 2004.
- A. Kubota, K. Takahashi, K. Aizawa, T. Chen, "All-focused light field rendering," Eurographics Symposium on Rendering (EGSR2004), June 21-23, 2004.
-
Akira Kubota, Kiyoharu Aizawa and Tsuhan Chen,
"Reconstructing dense light field from a multi-focus images
array," IEEE Conference on Multimedia
and Expo 2004,
Any suggestions or comments are welcome. Please send them to Akira Kubota