Extracting Adaptive Contextual Cues From Unlabeled Regions

[Paper][Poster][Slides][Video]
Abstract
Existing approaches to contextual reasoning for enhanced object detection typically utilize other labeled categories in the images to provide contextual information. As a consequence, they inadvertently commit to the granularity of information implicit in the labels. Moreover, large portions of the images may not belong to any of the manually-chosen categories, and these unlabeled regions are typically neglected. In this paper, we overcome both these drawbacks and propose a contextual cue that exploits unlabeled regions in images. Our approach adaptively determines the granularity (scene, inter-object, intra-object, etc.) at which contextual information is captured.
In order to extract the proposed contextual cue, we consider a scene to be a structured configuration of objects; just as an object is a composition of parts. We thus learn our proposed ``contextual meta-objects'' using any off-the-shelf object detector, which makes our proposed cue widely accessible to the community. Our results show that incorporating our proposed cue provides a relative improvement of 12% over a state-of-the-art object detector on the challenging PASCAL dataset.
Algorithm
Motivation
--Observations 1: To provide context for object detection, useful information must be relevant i.e. has consistent spatial location with respect to the object-of-interest, and information that is reliable i.e. has consistent appearance across images for reliable detection.
--Observations 2: Objects provide information for scene alignment.
-- Observation 3: Context around objects (potted-plant and dog shown in yellow boxes) can vary in extent (left) and content (right).

--Observations 4: Objects are to scenes as parts are to objects.
Approach
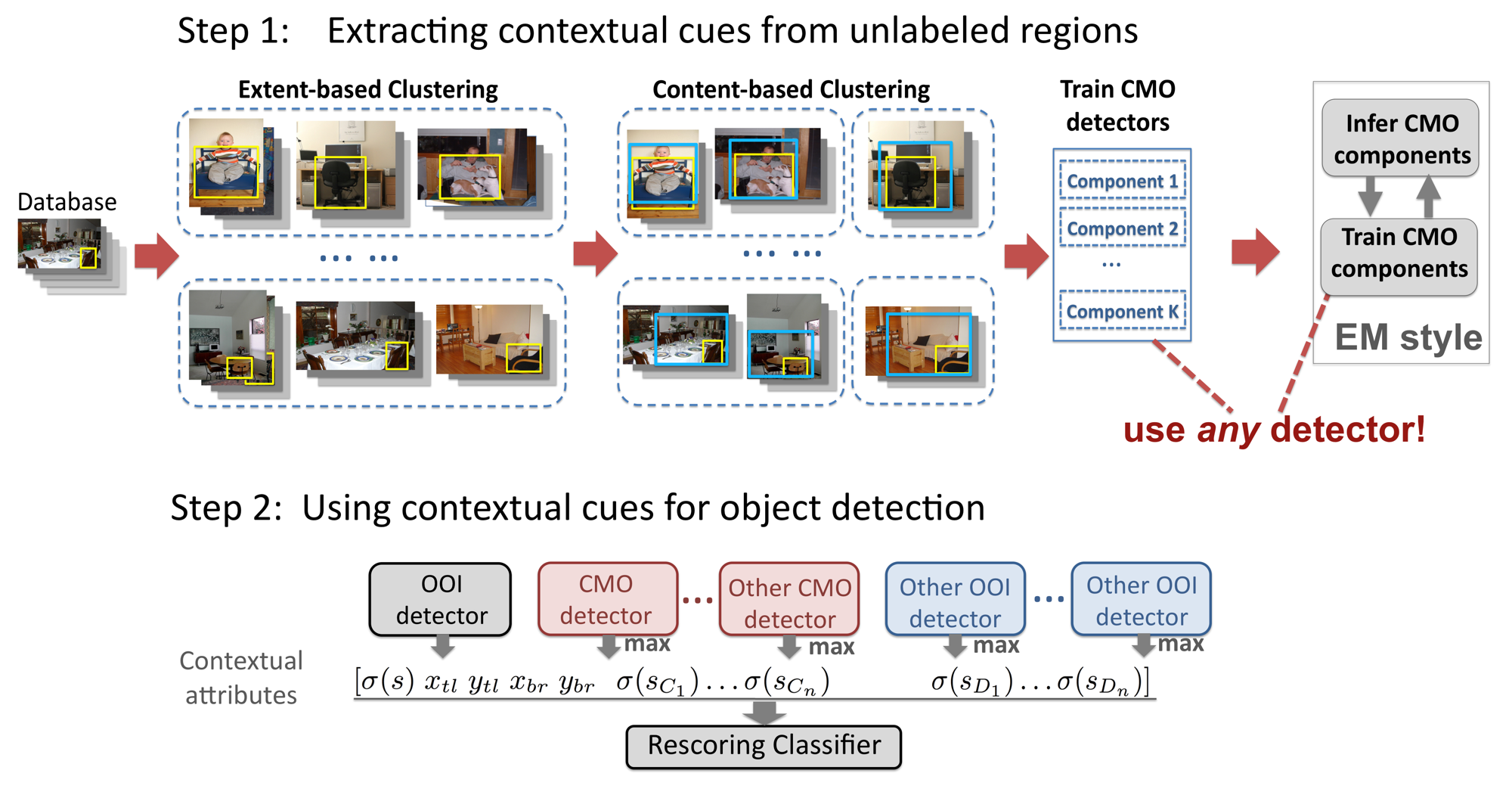
We model the contextual meta objects via object models. So the main contribution of our work is how we discover these Contextual-Meta-Objects (CMO) at adaptive granularity for each object category.
-- Training: To discover the CMOs from the unlabeled regions, it involves a two stage clustering process. Using the labeled Object-Of-Interest (OOI) bounding box as an anchor point, we first cluster all images containing the OOI according to the object location and scale. In the second stage, we further divide each cluster into 2 clusters based on the different contents around the objects, capture by a global gist descriptor of the image. We then determine the largest bounding box within each group that is smaller than 80% of the images in the group. This determines the granularity of context that will be captured. The resultant bounding boxes correspond to the CMOs. We then train a detector for this CMO category.
-- Testing: We apply the CMO detector on the test image, and the score of the detection captures our contextual cue. This cue can be combined with the OOI detection score, or other contextual cues for enhanced OOI detection (A rescoring classifier is trained with the training data).
Results
- Quantitative Results
Average Precision (AP) on PASCAL 2007 dataset

![]()
The mean AP across the 20 categories in PASCAL VOC 2007 for fusing various sources of contextual information
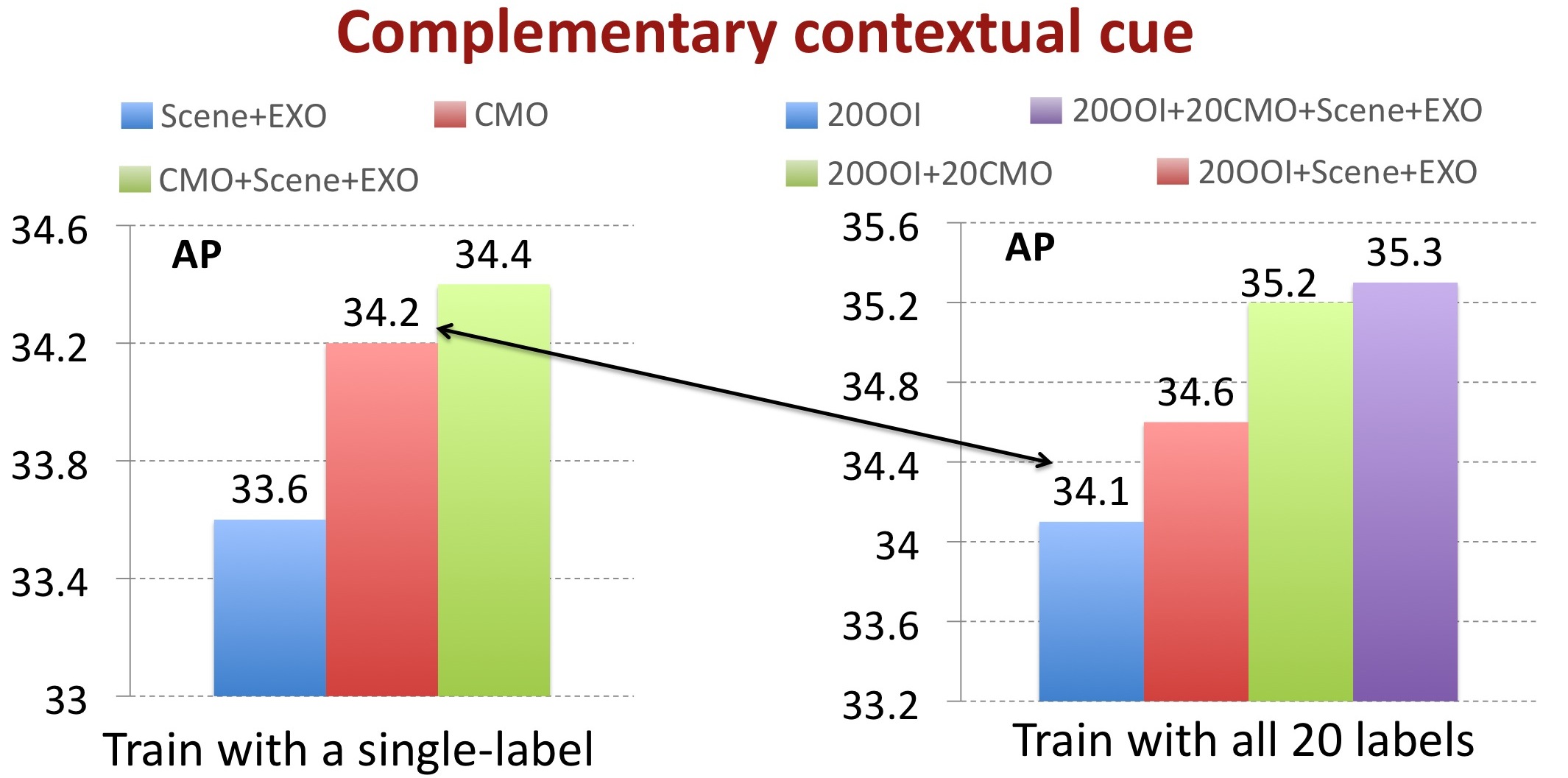
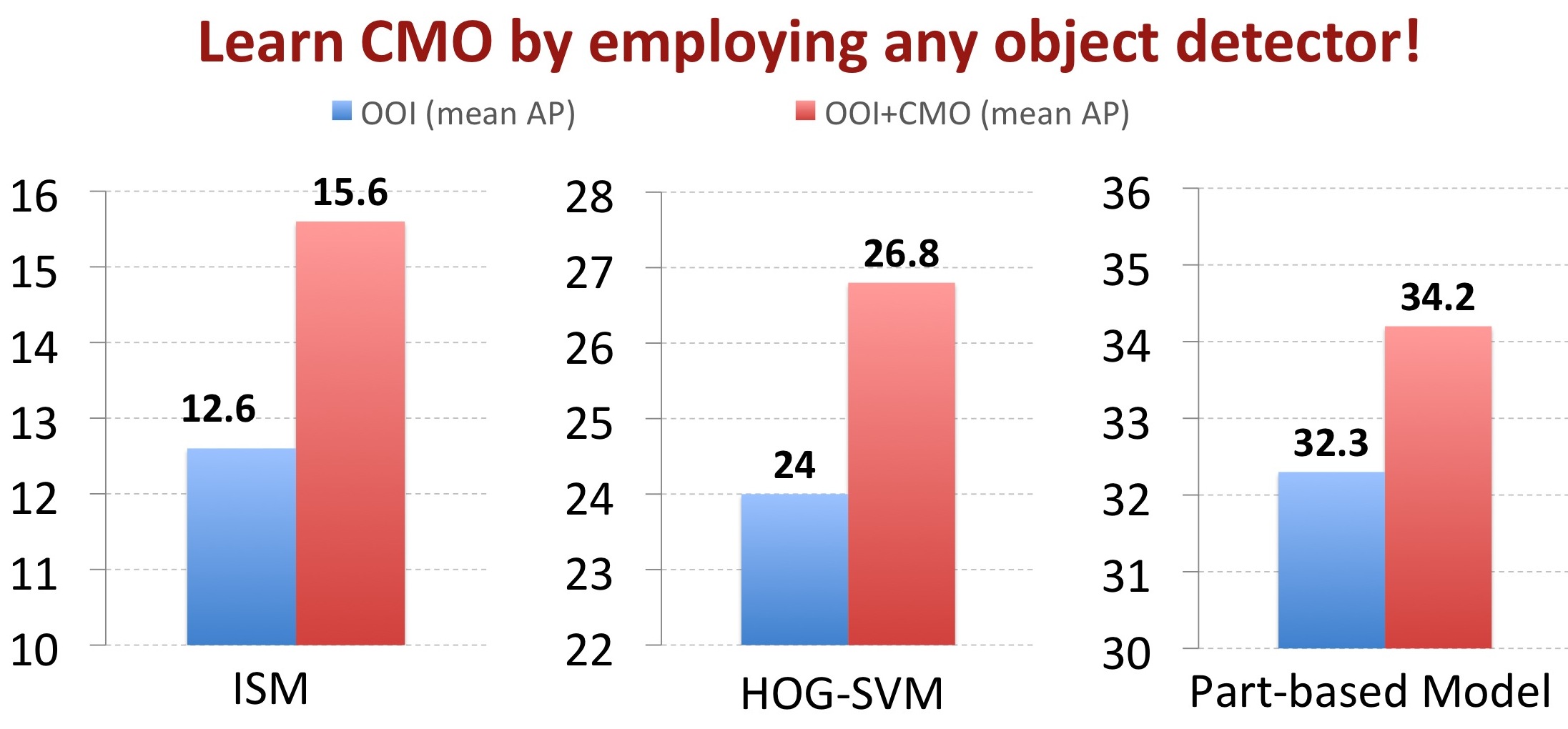
Detection results with and without the proposed CMO as additional contextual information by using different black-box detectors
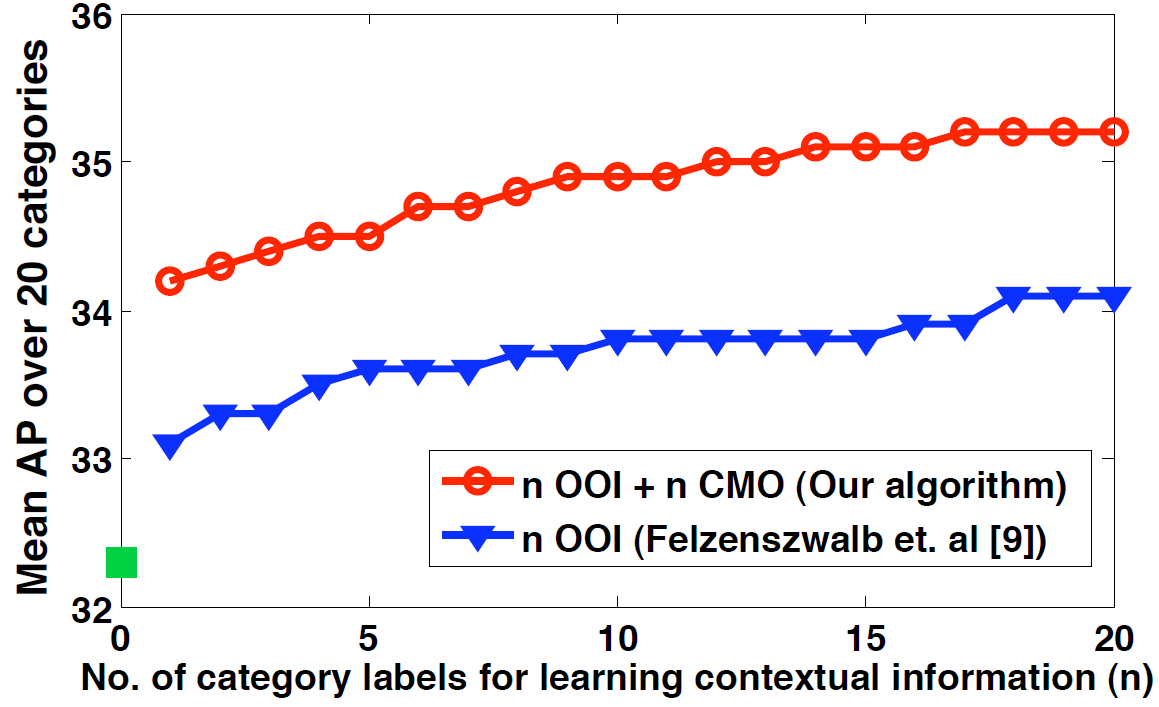
The effect of number of labeled categories on the mean AP (across 20 categories)
- Spatial Priming with the CMOs
The spatial maps indicate the likelihood of a person being present given the CMO detections (red boxes). We see that the CMO provides strong priming for locations of OOIs

- Examples of detected contextual meta-objects (CMO)
The first row shows the HOG feature visualizations of the leant CMO. Each image in the remaining rows shows the highest scoring CMO detection in that image. The red box indicates the CMO bounding-box, while the white boxes represent the “part” detections within the CMO as learnt by the deformable parts-based model [8]. Rows 2~5 are true-positive detections, and Rows 6~7 are false-positive detections. We consider a detection to be a false-positive if it occurs in an image that does not contain an object from the category of interest.




Publication
Congcong Li, Devi Parikh, Tsuhan Chen. “Extracting Adaptive Contextual Cues From Unlabeled Regions.” To appear in International Conference on Computer Vision (ICCV), 2011. [Paper][Poster][Slides][Video]