Revisiting Depth Layers from Occlusions
People
Adarsh Kowdle, Andrew Gallagher and Tsuhan Chen
Abstract
In this work, we consider images of a scene with a moving object captured by a static camera. As the object (human or otherwise) moves about the scene, it reveals pairwise depth-ordering or occlusion cues. The goal of this work is to use these sparse occlusion cues along with monocular depth occlusion cues to densely segment the scene into depth layers. In this paper, we cast the problem of depth-layer segmentation as a discrete labeling problem on a spatio-temporal Markov Random Field (MRF) that uses the motion occlusion cues along with monocular cues and a smooth motion prior for the moving object. We quanitatively show that depth ordering produced by the proposed combination of the depth cues from object motion and monocular occlusion cues are superior to using either feature independently, and using a naive combination of the features.
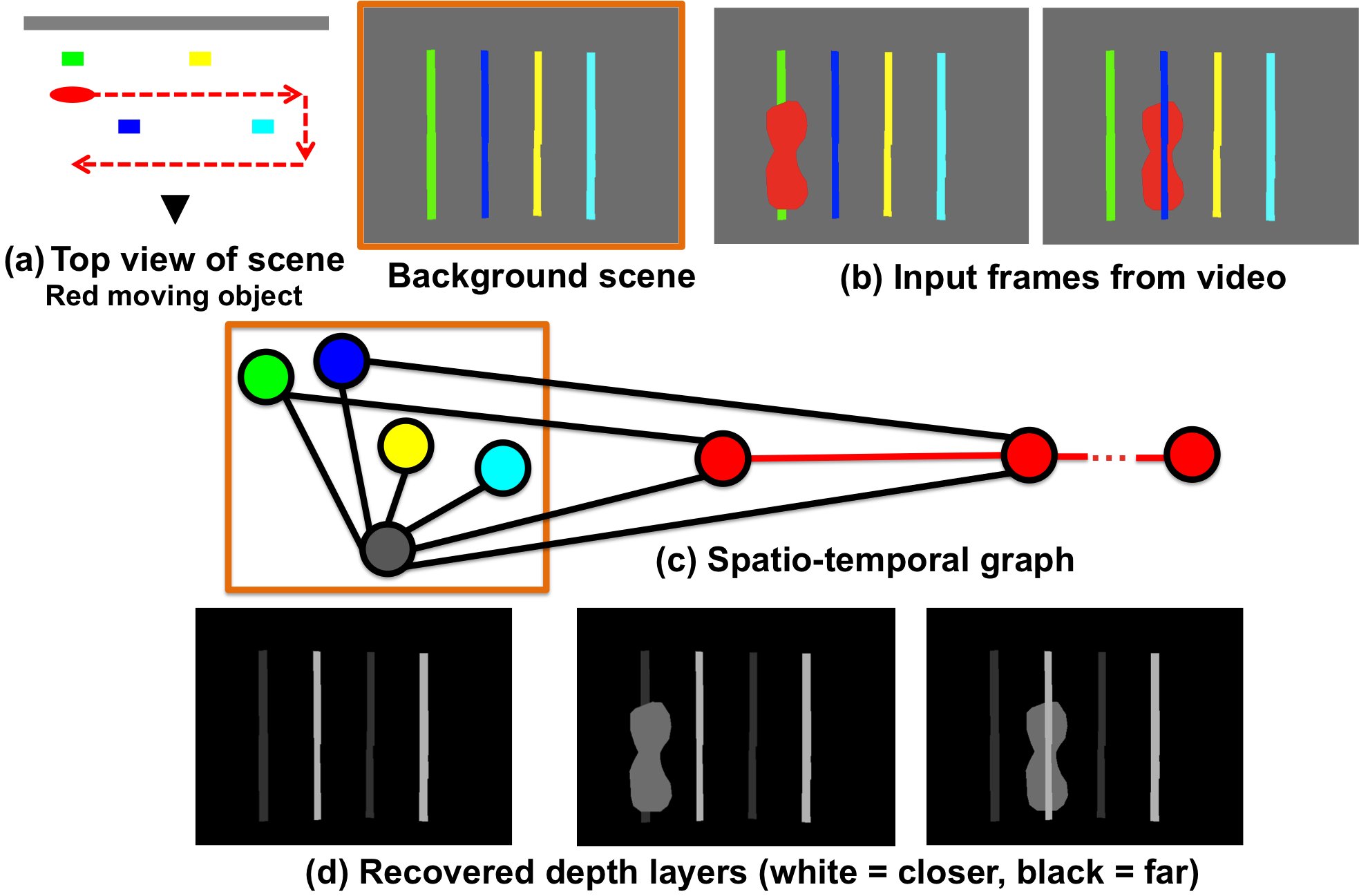
Overview figure. (a) Ground-truth top view, black triangle shows the camera looking up at a scene with the red moving object region following the path shown in the red arrow; (b) Shows the background scene in the orange box and two frames from the input sequence where the red object interacts with the background regions to reveal pairwise depth-ordering cues such as red occludes green, blue occludes red; (c) A graph constructed over the background regions is shown in the orange box. Each colored node corresponds to the respective colored region in (b). The red nodes correspond to the moving object with a node for every frame f in the input sequence ({1, 2, . . . , F }). The black edges enforce the observed pairwise depth-ordering, for instance between the green-red nodes at f = 1, and blue-red nodes at f = 2. The red edges enforce a smooth motion model for the moving object; (d) Shows the inferred depth layers, white = near and black = far.
Publications
- Adarsh Kowdle, Andrew Gallagher and Tsuhan Chen. "Revisiting Depth Layers from Occlusions", Computer Vision and Pattern Recognition (CVPR), 2013. [pdf]
Dataset
- Depth Layers Dataset [zip (1.2 GB)]. We provide here the dataset we use in our work. The dataset consists of input videos, the corresponding ground-truth depth layer annotation for each scene and, the manually labeled pixel-wise co-segmentation of the moving objects in case of multiple moving objects in the scene.