About AMP Lab Projects Downloads Publications People Links Project - Trademark Retrieval |

| Motivation and Goal |
In traditional trademark retrieval systems, the trademarks are first annotated with keywords that are then used for retrieval. However, this process requires a lot of manual labor in order to assign keywords. Also, the annotation for the same trademark may not be consistent with different users. As a result, it is more desirable to allow the user to input a query by providing a rough sketch and then the system is smart enough to automatically extract features from this query sketch and use them for comparison in order to search for similar trademarks in the database.
System Overview
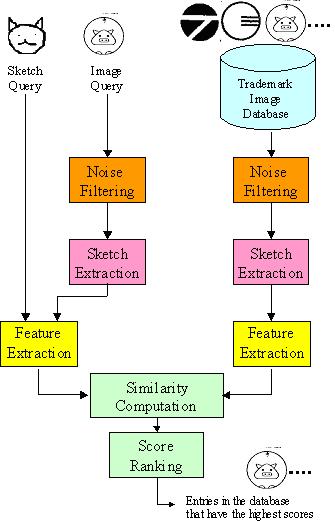
Figure 1. System overview of the trademark retrieval system
The trademarks are scanned binary images in which holes and spots may be presented as noise. Some filtering is applied in order to reduce such noise. We apply four 3×3 masks separately and the resulting image is obtained by combining the filtered output. Figure 2 shows an example of the images before filtering and after filtering, together with the resulting extracted sketch. It can be seen that the extracted sketch is much better with noise filtering.




Figure 2. Effect of noise filtering
The filtered image is first segmented into regions according to the pixel connectivity. For each region, either edge extraction is performed to extract the contour or thinning is performed to extract the skeleton. It is advantageous to use different methods under different situations. For example, for a solid region in which the shape conveys a lot of visual information, it is better to perform edge extraction to that region to extract the contour. On the other hand, for a region that contain curves, thinning should be performed to that region to extract the skeleton that is a better representation. To determine whether contour or skeleton is a better representation for a region, we look at the distribution of the distance between each pixel of the skeleton and the nearest pixel of the contour. For example, we would like to perform thinning for a region if the distance from the skeleton to the nearest boundary pixel is small and if this distance does not vary too much for different skeleton pixel values as shown in Figure 3(b). On the other hand, if there is a large variation in the distance from the skeleton pixel to the nearest boundary pixels, then edge extraction is preferred to extract the contour as shown in Figure 3(a). Therefore, the mean and variance of that distance distribution is used for classifying a region into skeleton-best or contour-best representation. After performing edge extraction or thinning for all the regions, the strokes are traced by examining the pixel connectivity starting from the end points. This results in two types of strokes: contour strokes which are obtained by edge extraction and skeleton strokes which are obtained by thinning.


Figure 3. Example regions that are suitable for edge extraction and for thinning, and their corresponding skeleton superimposed on the contour
Feature Extraction and Similarity Computation
After the sketches are extracted, the feature extraction and the similarity computation are based on the scheme we proposed for the sketch retrieval project. More information about these components can be found from the Hand-Drawn Sketch Retrieval Project page.
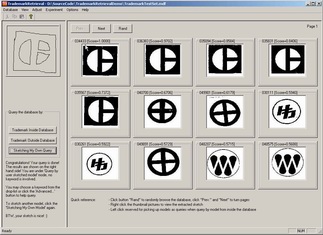
Our trademark retrieval interface is shown in Figure 4. After the user selects a database a trademarks, he/she can browse through the trademarks. A window will pop up after the user right clicks on the trademark image and the corresponding sketch extracted for that trademark will be shown. Moreover, he/she can click on the trademark to select that trademark to be the query and then trademarks in the database that are similar to the query will be retrieved. The query is shown on the frame in the left hand side. The twelve trademarks that have the highest ranks according to the similarity score are shown on the frame in the right hand side. In addition to trademark image, the user is also able to provide a sketch as a query, and the trademarks whose corresponding extracted sketches similar to the query sketch are retrieved and ranked as shown in Figure 4. Note that the query is merely a rough sketch yet the system is able to retrieve all the relevant trademarks with the highest similarity scores.
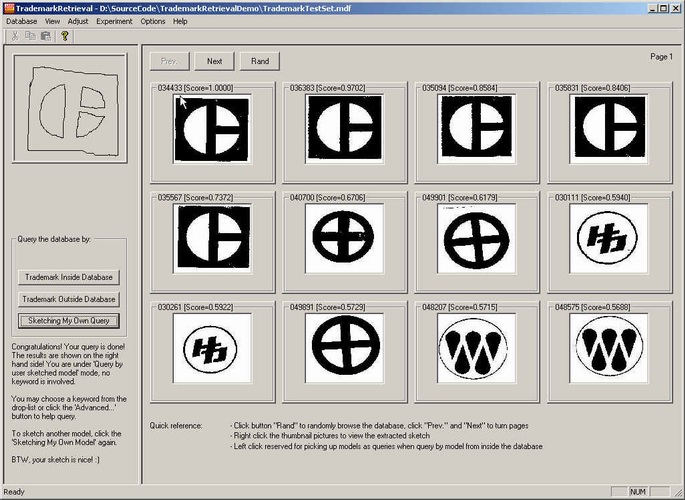
Figure 4. path-constrained rate shaping
Experiments and Results
Our database consists of close to two thousand trademarks. The ground truth of the database is obtained by classifying the trademarks in groups. Under each group the trademarks are similar to each other and one may be a transformed version of the other such as translation, rotation and scaling or may contain a different noise level. We first analyze the performance of our classifier for deciding whether an edge or skeleton should be extracted for each region. We pick 154 trademarks out of 43 classes as queries and then examine the rankings of the trademarks from the same classes. The same queries were used under 3 different conditions for the sketch extraction: 1) when thinning alone is applied to each region to extract the skeleton strokes; 2) when edge extraction alone is applied to extract the contour strokes; 3) when a classifier is used to decide whether thinning or edge extraction should be performed for each region so that a sketch may consist of both the skeleton strokes and the contour strokes. Some examples of the retrieval result using these three methods are shown in Figure 5. It can be seen that when contour strokes are used alone, solid regions and non-solids regions with similar shapes are treated the same way thus the retrieved trademark of rank 2 is considered to be more similar to the query than the retrieved trademark of rank 3. When skeleton strokes are used alone, solid regions shrink to the skeleton thus the retrieved trademark of rank 3 is considered to be more similar to the query than the retrieved trademark of rank 4. On the other hand, when contour-skeleton stroke classification is used, the system is able to distinguish between solid and non-solid regions even if they have similar shapes. The overall retrieval performance is shown in Figure 6 and is presented as the precision-recall graph. The precision-recall curve with higher precision at the same recall values means better retrieval performance. It can be seen that by classifying the sketch into skeleton strokes and edge strokes, the retrieval performance is better than the other two cases: 1) when thinning alone is performed for all regions to divide the sketch into all skeleton strokes; and 2) when edge extraction alone is performed for all the regions to divide the sketch into all contour strokes.
| Method | Query | Rank 1 | Rank 2 | Rank 3 | Rank 4 |
| Contour-Skeleton Stroke Classification | 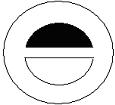 |
|
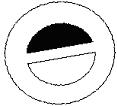 |
 |
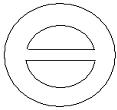 |
| Contour Strokes Alone | |
|
|
|
|
| Skeleton Strokes Alone | |
|
|
 |
|
Figure 5. Retrieval result under 3 different methods
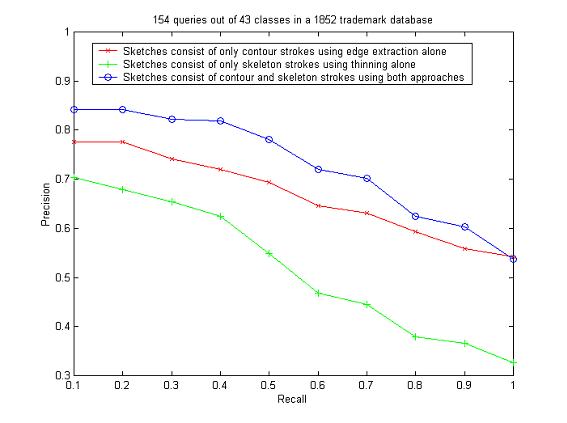
Figure 6. Comparison of retrieval performance
| Publications |
-
Wing Ho Leung and Tsuhan Chen, "Retrieval of sketches based on spatial relation between strokes", IEEE Intl. Conf. on Image Processing (ICIP 2002), Vol. 1, pp. 908-911, New York, September 2002.
-
Wing Ho Leung and Tsuhan Chen, "Trademark retrieval using contour-skeleton stroke classification", IEEE Intl. Conf. on Multimedia and Expo. (ICME 2002), Lausanne, Switzerland, August 2002.
Any suggestions or comments are welcome. Please send them to David Liu.
|