Learning to Segment a Video to Clips Based on Scene and Camera Motion
People
Adarsh Kowdle and Tsuhan Chen
Abstract
We present a novel learning-based algorithm for temporal segmentation of a video into clips based on both camera and scene motion, in particular, based on combinations of static vs. dynamic camera and static vs. dynamic scene. Given a video, we first perform shot boundary detection to segment the video to shots. We enforce temporal continuity by constructing a markov random field (MRF) over the frames of each video shot with edges between consecutive frames and cast the segmentation problem as a frame level discrete labeling problem. Using manually labeled data we learn classifiers exploiting cues from optical flow to provide evidence for the different labels, and infer the best labeling over the frames.
We show the effectiveness of the approach using user videos and full-length movies. Using sixty full-length movies spanning 50 years, we show that the proposed algorithm of grouping frames purely based on motion cues can aid computational applications such as recovering depth from a video and also reveal interesting trends in movies, which finds itself interesting novel applications in video analysis (time-stamping archive movies) and film studies.
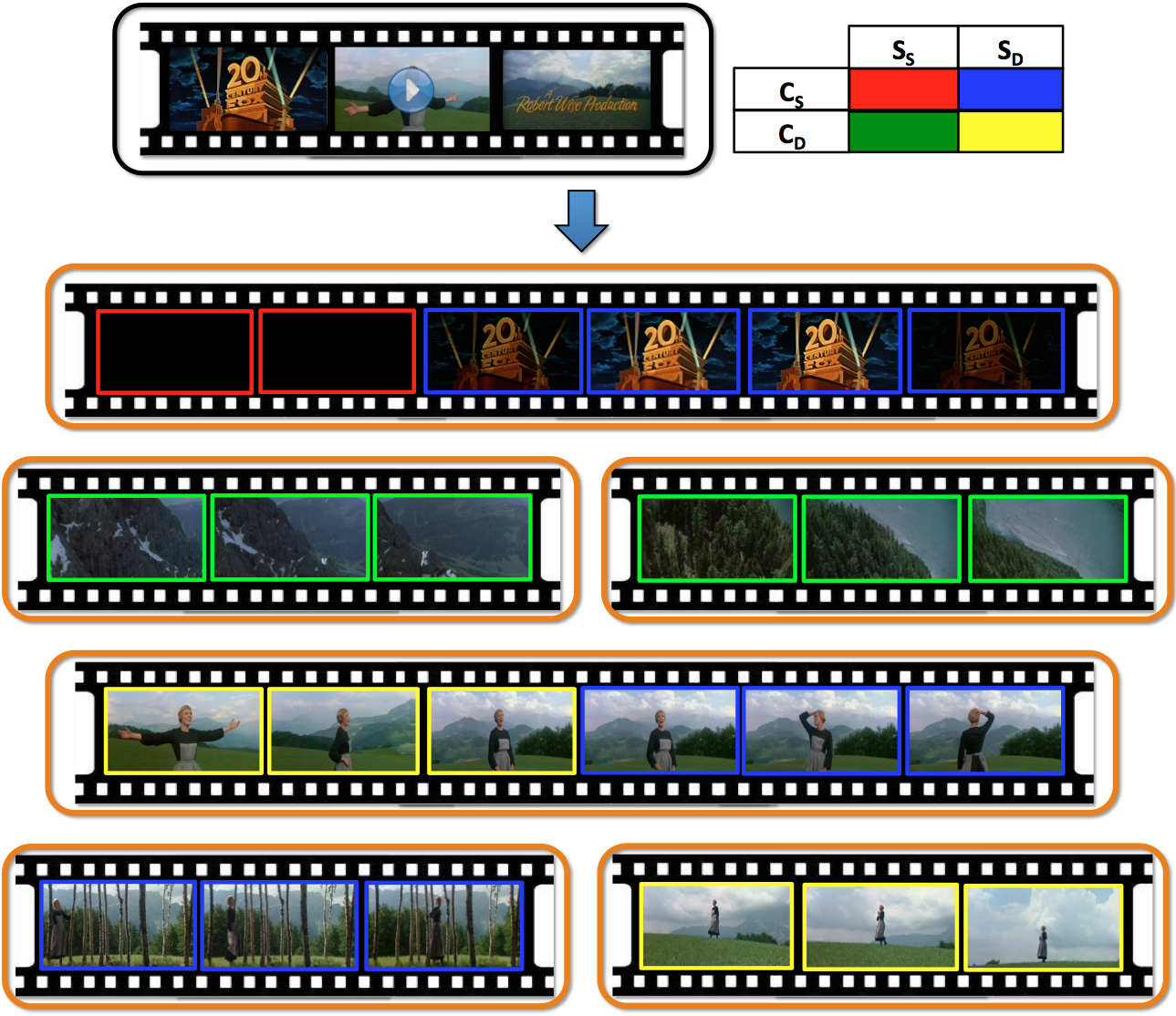
Figure: The proposed algorithm takes a video as input (black box) and first segments the video to shots, where each shot is the group of frames shown in an orange box. The algorithm segments the frames of each shot to clips based on scene and camera motion, expressed as combinations of static camera (C_S) vs. dynamic camera (C_D) and static scene (S_S) vs. dynamic scene (S_D), shown with red, green, blue and yellow borders around the frame (color code on first row). The above are some results of our algorithm on the movie Sound of Music.
Publications
- Adarsh Kowdle and Tsuhan Chen. "Learning to Segment a Video to Clips Based on Scene and Camera Motion", European Conference on Computer Vision (ECCV), 2012. [pdf]
Video showing some results using the proposed approach
Dataset
We introduce the manually labeled video to clips dataset used for the quantitative analysis in our paper. Cornell Video2Clips Dataset.
The dataset we refer to as Set-A in the paper consists of five user videos and one full-length movie (Sound of Music). We sample the videos at a frame rate of 10fps giving us a total of about 110,000 frames. We manually label the frames with one of four discrete labels we define in this work i.e. the four combinations of Static vs. Dynamic camera and Static vs. Dynamic scene. These frame labels are provided in the zip file. While we do not re-distribute the movie, we provide the frame level labels corresponding to the movie.
The second subset of the dataset we refer to as Set-B in the paper consists of 60 full-length movies spanning from 1960-2010 with 12 movies from each decade. We make this list of movies we use in this work publicly available here. [Cornell Video2Clips Movies]
If you use the 'Cornell Video2Clips Dataset' in your research, please cite the following paper,
- Adarsh Kowdle and Tsuhan Chen. "Learning to Segment a Video to Clips Based on Scene and Camera Motion", European Conference on Computer Vision (ECCV), 2012.
Acknowledgement
We thank Jordan DeLong for collecting and sharing the hollywood movies across decades.