Automatic Discovery of Groups of Objects for Scene Understanding

We automatically discover and model "groups of objects" which are complex composites of objects with consistent spatial, scale, and view-point relationship across images. These groups can aid detection of participating objects (e.g. umbrella in (a)) or non-participating objects (e.g. fence in (b)) as well as improve scene recognition (e.g. dining room vs. meeting room in (c) and (d)).
Abstract
Objects in scenes interact with each other in complex ways. A key observation is that these interactions manifest themselves as predictable visual patterns in the image. Discovering and detecting these structured patterns is an important step towards deeper scene understanding. It goes beyond using either individual objects or the scene as a whole as the semantic unit. In this work, we promote ``groups of objects''. They are high-order composites of objects that demonstrate consistent spatial, scale, and viewpoint interactions with each other. These groups of objects are likely to correspond to a specific layout of the scene. They can thus provide cues for the scene category and can also prime the likely locations of other objects in the scene.
It is not feasible to manually generate a list of all possible groupings of objects we find in our visual world. Hence, we propose an algorithm that automatically discovers groups of arbitrary numbers of participating objects from a collection of images labeled with object categories. Our approach builds a 4-dimensional transform space of location, scale and viewpoint, and efficiently identifies all recurring compositions of objects across images. We then model the discovered groups of objects using the deformable parts-based model. Our experiments on a variety of datasets show that using groups of objects can significantly boost the performance of object detection and scene categorization.
Group Discovery Algorithm
Step 1: Find common object patterns between every image-pair through a 4-dimensional transform space.
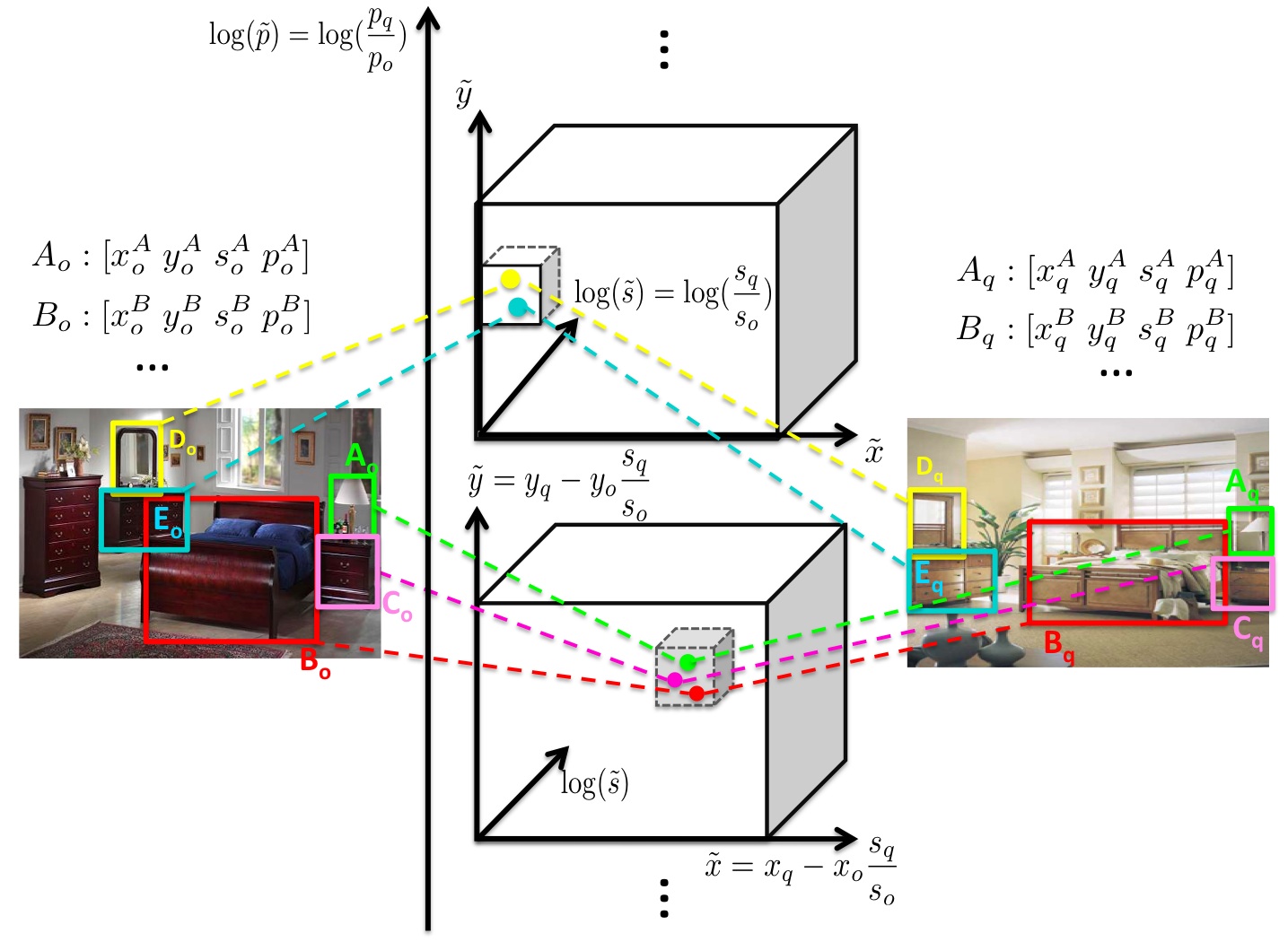
Step 2: Clustering patterns into groups by assuming transidivity between patterns. Allow missing participating objects: low-order groups' instantiations are merged with high-order group instantiations.
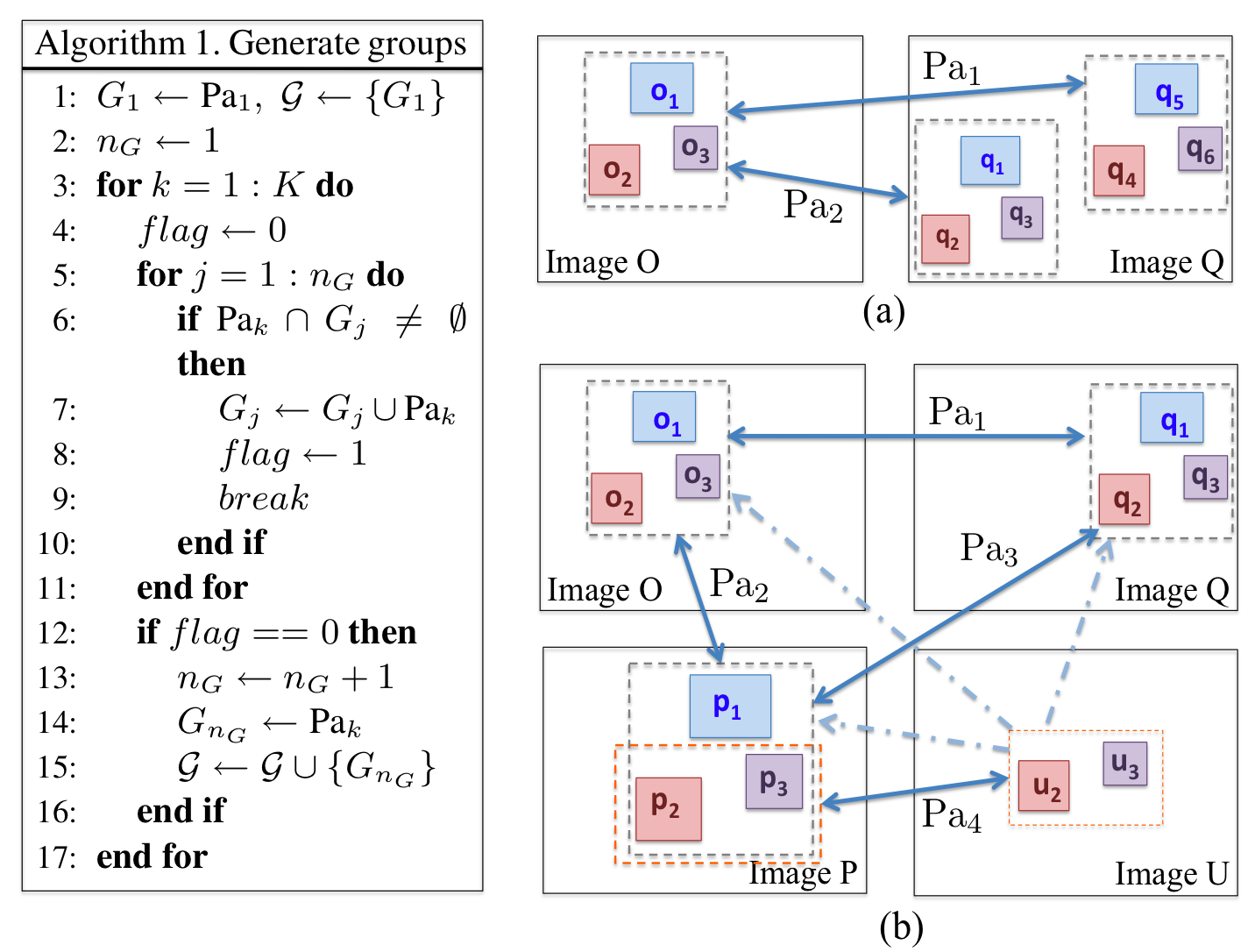
Step 3: Training group detectors.
-- Generate a bounding box for each instantiation of the group: the smallest box that encompasses all participating objects including the hallucinated missing object.
-- Utilize any off-the-shelf object detection method to train group detectors. We used the deformable part-based model.
Contextual Reasoning Algorithm
We utilize the groups to enhance two scene understanding tasks: object detection and scene recognition. For object detection, we rescore a candidate OOI detection using a classifier that incorporates the highest detections of groups of objects in the image. For scene categorization, we represent an image using a feature vector with each dimension indicating the highest score among the detections of a certain group on the image, and then train SVM classifiers with RBF kernel for classification. The outputs are then combined with those from other classifiers which take different feature inputs (e.g. GIST feature, highest scores of object detections, etc).

Results
- Results for group discovery
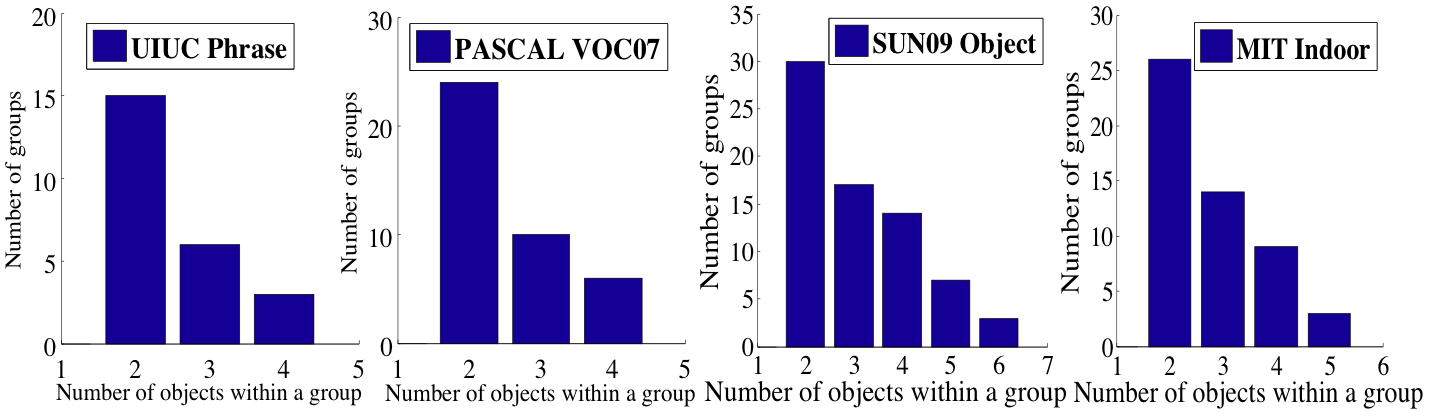
Distribution of the number of objects within our automatically discovered groups of objects using four datasets. We can discover a diverse set of high-order groups.
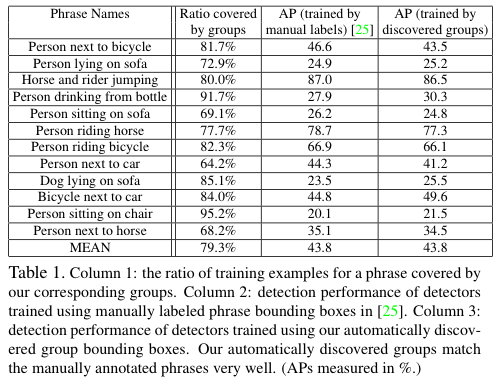
Evaluation on how well our automatically discovered groups correspond to the hand-generated list of 12 groups containing two objects.
- Results for enhanced scene understanding
Object Detection: Average Precision (AP) on UIUC Phrasal dataset. Methods: Baseline without context; Object context (rescoring using other objects); Phrase context (rescoring using the manually defined phrases); Group context (rescoring using our automatically discovered object groups).

Object Detection: Average Precision (AP) on PASCAL 2007 dataset

Object Detection: Average Precision (AP) on SUN09 Object dataset

Scene Recognition: Average Precision (AP) on MIT Indoor dataset

- Examples of discovered groups on various datasets
Examples of our automatically discovered groups of objects from four datasets.

Publication
Congcong Li, Devi Parikh, Tsuhan Chen. “Automatic Discovery of Groups of Objects for Scene Understanding.” In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012. [Paper][Poster]
References(*Only the references cited on this page are listed. For a full list, please refer to the paper.)
[2] M. J. Choi, J. J. Lim, A. Torralba, and A. S. Willsky. Exploiting hierarchical context on a large database of object categories. In CVPR, 2010.
[6] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part-based models. PAMI, IEEE Transactions on, 32(9):1627 –1645, Sep. 2010.
[15] C. Li, D. Parikh, and T. Chen. Exploiting regions void of labels to extract adaptive contextual cues. In ICCV, 2011.
[18] M. Pandey and S. Lazebnik. Scene recognition and weakly supervised object localization with deformable part-based models. In ICCV, 2011.
[25] M. A. Sadeghi and A. Farhadi. Recognition using visual phrases. In CVPR, 2011.