Spoken Attributes:
Mixing Binary and Relative Attributes to Say the Right Thing
People
Amir Sadovnik, Andrew Gallagher, Devi Parikh, Tsuhan Chen
Abstract
In recent years, there has been a great deal of progress in describing objects with attributes. Attributes have proven useful for object recognition, image search, face verification, image description, and zero-shot learning. Typically, attributes are either binary or relative: they describe either the presence or absence of a descriptive characteristic, or the relative magnitude of the characteristic when comparing two exemplars. However, prior work fails to model the actual way in which humans use these attributes in descriptive statements of images. Specifically, it does not address the important interactions between the binary and relative aspects of an attribute. In this work we propose a spoken attribute classifier which models a more natural way of using an attribute in a description. For each attribute we train a classifier which captures the specific way this attribute should be used. We show that as a result of using this model, we produce descriptions about images of people that are more natural and specific than past systems.
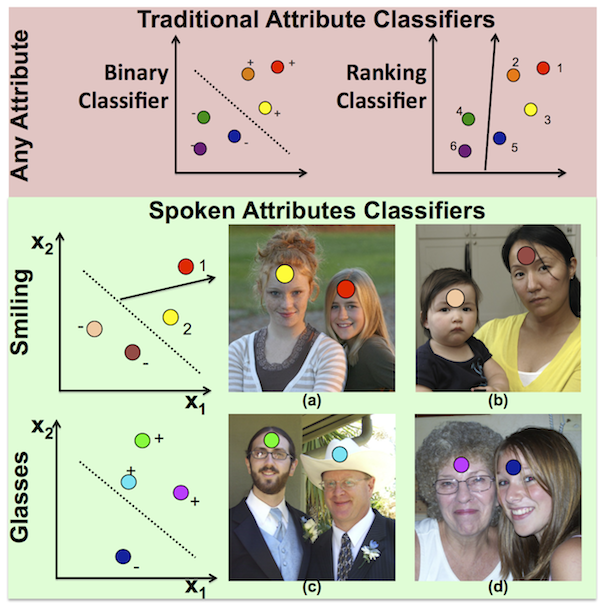 |
| Previous work has focused on attributes as being exclusively either binary or relative. However, real attributes usually do not simply fall into one of those two categories. For example, for image (a) one might say "The person on the right is smiling more than the person on the left"'. However, in image (b), where neither face is smiling, using such a relative smiling statement does not make sense. For the glasses attribute it never makes sense to use a relative description even though a ranker output for image (d) would suggest that the person on the left has "more glasses" than the person on the right. In this paper we propose a unified spoken attribute classifier that learns this mapping for each attribute and can "say the right thing."' |
Publication
A. Sadovnik, A. Gallagher, D. Parikh and T. Chen. "Spoken Attributes: Mixing Binary and Relative Attributes to Say the Right Thing", International Conference on Computer Vision (ICCV), 2013.
Data Set
We provide the images of pairs of people we used in our experiments (a subset of The Images of Groups Dataset), including the ground truth labels for 6 attributes regarding the three different types of questions we collected from Amazon Mechanical Turk Users. This includes binary data (which people have/do not have the attribute), relative data (which person has more of the attribute), and our spoken attribute (most accurate description). For more details please see our paper and the readme file included in the zipped folder.
Download Data Set (49MB)