What makes the task of face recognition so difficult? We propose that it
is the ability to generalize to unseen contextual conditions (e.g. pose,
lighting, expression, etc.) is at the cornerstone of the problem,
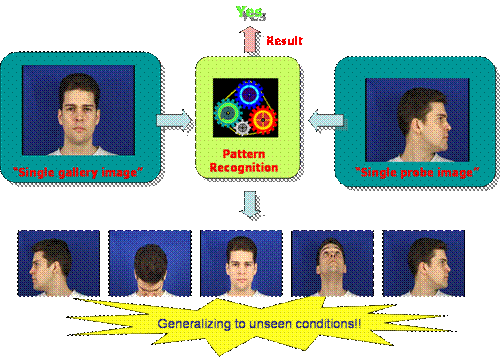
Recently we have been conducting work on techniques that allow for better
generalization in terms of the representation employed and the techniques
used to estimate a client's face biometric template. Recently we have
conducted work demonstrating that good verification performance can be
attained by relaxing many of the spatial constraints in the canonical
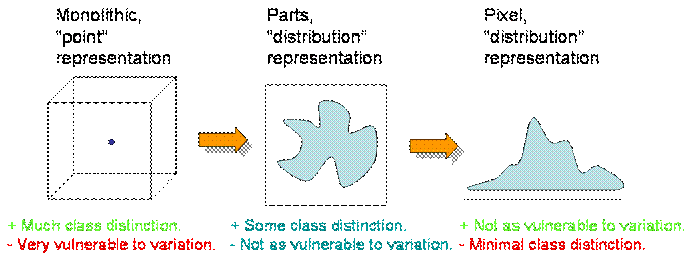
monolithic face representation. The technique departs from the traditional
idea of comparing gallery and probe faces or facial features as "points",
placing greater emphasis on the creation and comparison of gallery and probe
images as "distributions". The distributions are created by relaxing spatial
constraints in the face image, such that the position of the parts (i.e.
image patches) has no bearing on the final similarity measure. Through this
technique very good verification performance can be attained from collapsing
spatial constraints to generate a distribution of parts. Our work is
primarily motivated by the hypothesis that monolithic "point" based face
representations are much more prone to variations (e.g. pose, expression,
face frame) relative to parts "distribution" based representations.
Related papers:-
- S. Lucey, "The symbiotic relationship of parts and monolithic face
representations in verification," presented at International Workshop on
Face Processing in Video (FPIV), Washington D.C., 2004. [similar
technical report]
- S. Lucey and T. Chen, "A GMM parts based face representation for improved verification through relevance adaptation," presented at International Conference on Computer Vision and Pattern Recognition (CVPR), Washington D.C., 2004.
[similar technical report]
(This page is still under construction!!!)
 Top of Research Interests
Top of Research Interests
