|
About
AMP Lab
Projects
Downloads
Publications
People
Links
Project - Active Learning
 Top of this page
Top of this page
Hidden annotation has been proved to be a powerful
tool to bridge the gap between low-level features and high-level semantic
meanings in a retrieval system. We propose to use active learning to improve the
efficiency of hidden annotation. Active learning has been studied in the machine
learning literature. For
many types of machine learning algorithms, one can find the statistically "optimal"
way to select the training data. This was given the name active learning.
Although in traditional machine learning research, the learner typically works
as the recipient of data to do training, active learning enables the learner to
use his own ability to respond, to collect data, and to influence the world he
is trying to understand. To be more precise, what we are interested here is a
specific form of active learning, i.e., selective sampling. The goal of
selective sampling is to reduce the number of training examples that need to be
labeled by examining unlabeled examples and selecting the most informative ones
for the human to annotate.
Top of this page
We propose a general
active learning framework for content-based information retrieval. We use this
framework to guide hidden annotations in order to improve the retrieval
performance. For each object in the database, we maintain a list of
probabilities, each indicating the probability of this object having one of the
attributes. During training, the learning algorithm samples objects in the
database and presents them to the annotator to assign attributes to. For each
sampled object, each probability is set to be one or zero depending on whether
or not the corresponding attribute is assigned by the annotator. For objects
that have not been annotated, the learning algorithm estimates their
probabilities with kernel regression. Furthermore, the normal kernel regression
algorithm is modified into a biased kernel regression, so that an object that is
far from any annotated object will receive an estimate result of the prior
probability. This is based on our basic assumption that any annotation should
not propagate too far in the feature space if we cannot guarantee that the
feature space is good. Knowledge gain is then defined to determine, among the
objects that have not been annotated, which one the system is the most uncertain
of, and present it as the next sample to the annotator to assign attributes to.
During retrieval, the list of probabilities works as a feature vector for us to
calculate the semantic distance between two objects, or between the user query
and an object in the database. The overall distance between two objects is
determined by a weighted sum of the semantic distance and the low-level feature
distance. The algorithm is tested on both synthetic database and real database.
In both cases the retrieval performance of the system improves rapidly with the
number of annotated samples. Furthermore, we show that active learning
outperforms learning based on random sampling.
Our
algorithm is best illustrated with a synthetic example. The database we
constructed have three categories, and one of them has two subcategories, as is
shown in the next several figures. Around 2000 samples are included in this
database.
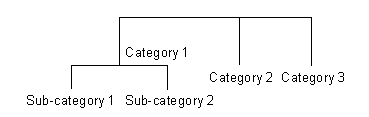
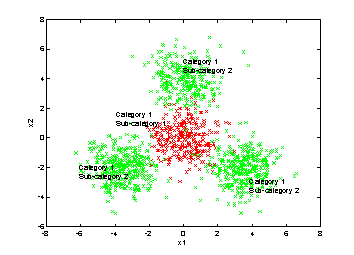
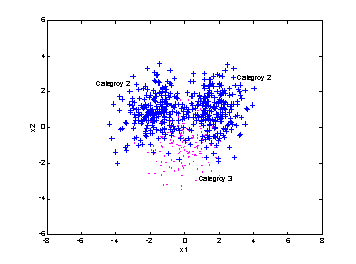
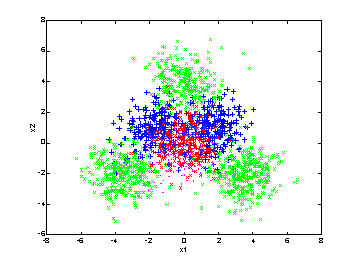
The
synthetic database.
At the initialization stage, we randomly sample 50 points to start, as shown
below. Black boxes represent samples that have been annotated.
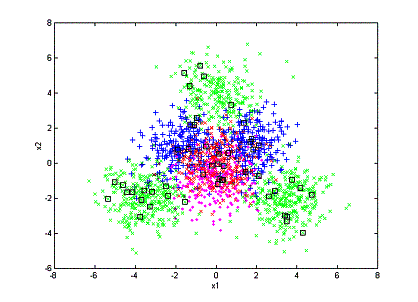
In
the initialization step, 50 objects are chosen randomly and annotated
We
can then compare the processes of annotation the two methods have:
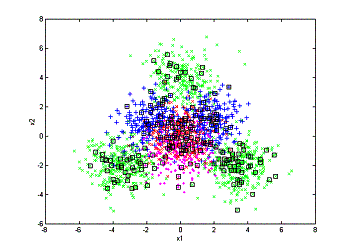
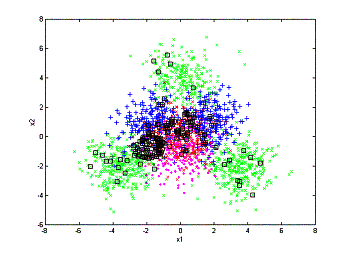
(a)
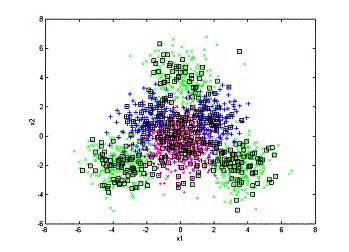
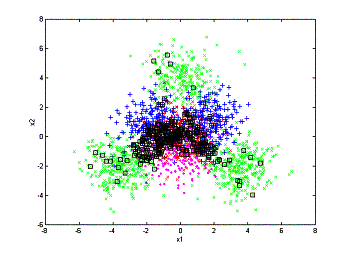
(b)
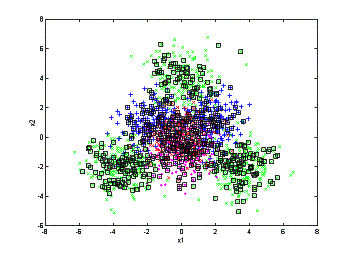
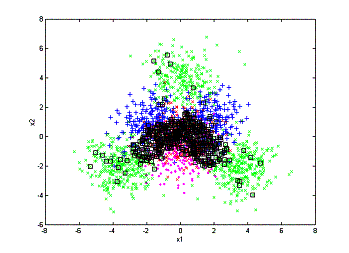
(c)
The
annotation processes. left: random sampling; right: active learning
(a) 200 objects annotated. (b) 400
objects annotated. (c) 600 objects annotated.
From
the above figures we can see that random sampling wastes a lot of annotation on
areas that the low-level feature is already very good for retrieval. As a
comparison, the active learning algorithm focuses on annotating the confusing
area and leaves the unconfusing area untouched. This is the major reason that
active learning can outperform the random sampling algorithm.
For
more details about our work, please refer to our technical report. .
Top of this page
- A demo video can be downloaded here
(7.6 MB).
Top of this page
-
C.
Zhang and T. Chen, "A New Active Learning Approach for Content-Based
Information Retrieval", IEEE Trans. on Multimedia Special
Issue on Multimedia Database, pp. 260-268, Vol. 4, No. 2, Jun 2002.
-
C. Zhang and T.
Chen, "Annotating Retrieval Database with Active Learning",
submitted to ICIP2003, Barcelona, Spain, Sep. 2003.
-
C.
Zhang and T. Chen, "An
Active Learning Framework for Content-Based Information Retrieval",
Carnegie
Mellon Technical Report: AMP01-04 .
Top of this page
Any suggestions or comments are welcome. Please
send them to Cha Zhang.
Top of this page
|
