 |
About AMP Lab Projects Downloads Publications People Links
Project - Audio-Visual Speech Processing
A human listener can use visual cues, such as lip and tongue movements, to enhance the level of speech understanding, especially in a noisy environment. The process of combining the audio modality and the visual modality is referred to as speechreading, or lipreading. Inspired by human speechreading, the goal of this project is to enable a computer to use speechreading for higher speech recognition accuracy.
There are many applications in which it is desired to recognize speech under extremely adverse acoustic environments. Detecting a person's speech from a distance or through a glass window, understanding a person speaking among a very noisy crowd of people, and monitoring a speech over TV broadcast when the audio link is weak or corrupted, are some examples. In these applications, the performance of traditional speech recognition is very limited. In this project, we use a video camera to track the lip movements of the speaker to assist acoustic speech recognition. We have developed a robust lip-tracking technique, with which preliminary results have showed that speech recognition accuracy for noisy audio can be improved from less than 20% when only audio information is used, to close to 60% when lip tracking is used to assist speech recognition. Even with the visual modality only, i.e., without listening at all, lip-tracking can achieve a recognition accuracy close to 40%.
We explore the problem of enhancing the speech recognition in noisy environments (both Gaussian white noise and cross-talk noise cases) by using the visual information such as lip movements.
We use a novel Hidden Markov Model (HMM) to model the audio-visual bi-modal signal jointly, which shows promising result for recognition. We also explore the fusion of the acoustic signal and the visual information with different combinations approaches, to find the optimum method.
To test the performance of this approach, we add gaussian noise to the acoustic signal with different SNR (signal-to-noise ratio). Here we plot the recognition ratio versus SNR.

In the plot above, the blue curve shows the change of the recognition ratio vs. SNR when we use the audio-visual joint feature (cascade the visual parameter with the acoustic feature) as the input to the recognition system. The black curve with "o" shows the performance when we use acoustic signal as the input, just as most conventional speech recognition systems do. The flat black curve shows the performance of recognition using only the lip movement parameters.
We can see that the recognition ratio of the joint HMM system drops much slower than the acoustic only system, which means the joint system is more robust to the gaussian noise corruption in the acoustic signal. We also apply this approach to cross-talk noise corrupted speech.
As the first step of this research, we collected an audio-visual data corpus, which is available to the public. In this data set, we have:
-
10 subjects (7 males and 3 females).
- The vocabulary includes 78 isolated words commonly used for time, such as, "Monday", "February", "night", etc. Each word repeated 10 times.
- Data Collection:
To collect a database with high quality, we have been very critical about the recording environment. We have set it up in a soundproof studio to collect noise-free audio data. And we used controlled light and blue-screen background to collect the image data.
We used a SONY digital camcorder with tie-clip microphone to record the data on DV tapes. The data on DV tapes is transferred to a PC by the Radius MotoDV program and stored as Quicktime files. Since the data on the DV tapes are already digital, there's no quality loss when transferred to the PC.
Here are some sample Quicktime videos: ( Here the Quicktime files have been converted to streaming RealVideo sequences with lower quality, to make online viewing easier. ) Click the image to view the sample video.










We have altogether 100 such Quicktime files, each one containing one subject articulates all the words in the vocabulary. Each file is about 450MBytes. Both the DV raw data and the Quicktime files are available upon request.
-
Data Pre-processing:
The raw data on the DV tapes and the Quicktimes files are big and need further processing before can be used directly in the lipreading research. We have processed the data in the following way:
First of all, for the video part, we only keep the mouth area since it's the Area of Interest in the lipreading research field. We used a video editing tool (such as Adobe Premiere) to crop out the mouth area. The following figure shows how the whole face picture, size 720*480, was cut to the only picture of the mouth, size 216*264. Note that the face in the original Quicktime video frame lie horizontally due to the shooting procedure.

The four offsets of the mouth picture were noted down for calculating the positions of the lip parameters later. After that, we shrank the mouth picture from size 216*264 to 144*176, and rotated to the final picture, size 176*144, the standardized QCIF format.
And then we use a lip tracking program to extract the lip parameters from each QCIF sized file, based on deformable template and color information. The template is defined by the left and right corners of the mouth, the height of the upper lip, and the height of the lower lip. The following figure shows an example of the lip tracking result, with the template in black lines superimposed on the mouth area.
Click the image to view the sample video sequence.For more details about the lip tracking and object tracking, please see our face tracking web page. The face tracking toolkit can be extended to track lip movements. The lip parameters are stored in text files, along with the offsets of the mouth picture.
Secondly, we also have the waveform files extracted from the Quicktime video files. These waveform files contains the speech signals corresponding to the lip parameters contained in the text files mentioned above.
-
Data Format
Text files with the lip parameters. The text file contains approximately 3000-4000 lines of numbers. The first line has four numbers which are the offsets of the picture when we cropped the mouth area from the whole face picture. Those four number are the left offset, the right offset, the top offset and the bottom offset respectively, as mentioned above.
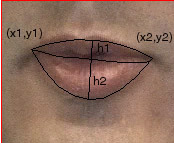
For the rest of numbers, each line is consist of seven numbers. The first one is the frame number. The next four numbers are the positions of the left corner(x1,y1) and the right corner(x2,y2). The last two numbers are the the height of the upper lip(h1), and the height of the lower lip(h2). As shown in the figure above.
1
2
3
4
5
6
7
Frame No.
x1
y1
x2
y2
h1
h2
The waveform files. These files contains audio signals which are sampled as PCM, 44.1KHz, 16 bit, mono.
-
Vocabulary
For date/time: One, two, three, four, five, six, seven, eight, nine, ten,
eleven, twelve, thirteen, fourteen, fifteen, sixteen, seventeen, eighteen, nineteen, twenty,
thirty, forty, fifty, sixty, seventy, eighty, ninety, hundred,
thousand, million, billionFor month:
January, February, March, April, May, June,
July, August, September, October, November, DecemberFor day:
Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday Some additional words:
Morning, noon, afternoon, night, midnight, evening,
AM, PM, now, next, last, yesterday, today, tomorrow,
ago, after, before, from, for, through, until, till, that, this, day, month, week ,year
| Publications |
-
F. J. Huang and T. Chen, "Real-Time Lip-Synch Face Animation driven by human voice", IEEE Workshop on Multimedia Signal Processing, Los Angeles, California, Dec 1998
Any suggestions or comments are welcome. Please send them to Wende Zhang.