Yimeng Zhang
Research Focus
- Computer vision
- Machine Learning
- Information Retrieval
- Data Mining
Current Research
Event Recognition from Videos
We develop algorithms to detect events from videos. (To be updated)
Fully-Connected CRFs for Image Labeling
The Conditional Random Field (CRF) is a popular tool for object-based image segmentation. CRFs used in practice typically have edges only between adjacent image pixels. To represent object relationship statistics beyond adjacent pixels, prior work either represents only weak spatial information using the segmented regions, or encodes only global object co-occurrences. In this paper, we propose a unified model that augments the pixel-wise CRFs to capture object spatial relationships. To this end, we use a fully connected CRF, which has an edge for each pair of pixels. The edge potentials are defined to capture the spatial information and preserve the object boundaries at the same time. Traditional inference methods, such as belief propagation and graph cuts, are impractical in such a case where billions of edges are defined. Under only one assumption that the spatial relationships among different objects only depend on their relative positions (spatially stationary), we develop an efficient inference algorithm that converges in a few seconds on a standard resolution image, where belief propagation takes more than one hour for a single iteration.
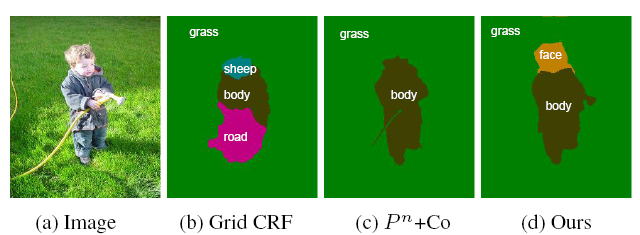
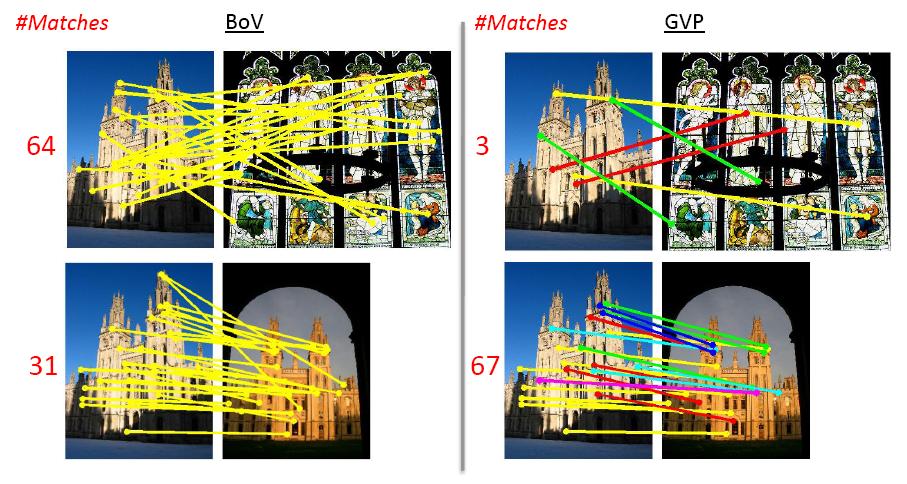
Image Retrieval with Geometry Preserving Visual Phrases
Similar image retrieval has attracted increasing interests in recent years. Given a query image or region, the goal is to retrieve the images of the same object or scene from a large database and return a ranked list.
The most popular approach to this problem is based on the bag-of-visual-word (BoV) representation of images. The spatial information is usually re-introduced as a post-processing step to re-rank the retrieved images, through a spatial verification like RANSAC. Since the spatial verification techniques are usually computationally expensive, they can be applied only to the top images in the initial ranking. In this work, we propose an approach that can encode more spatial information into BoV representation and that is efficient enough to be applied to large-scale databases. Other works pursuing the same purpose have proposed exploring the word co-occurrences in the neighborhood areas. Our approach encodes more spatial information through the geometry-preserving visual phrases (GVP). In addition to co-occurrences, the GVP method also captures the local and long-range spatial layouts of the words. Our GVP based searching algorithm increases little memory usage or computational time compared to the BoV method. Moreover, we show that our approach can also be integrated to the min-hash method to improve its retrieval accuracy.
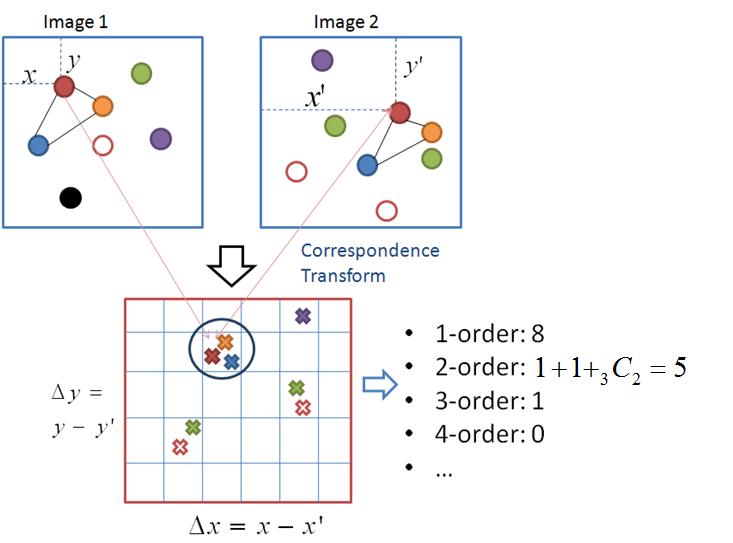
Unbounded Order Features for Object Recognition and Detection
Higher order spatial features, such as doublets or triplets have been used to incorporate spatial information into the bag-of-local-features model. Due to computational limits, researchers have only been using features up to the 3rd order, i.e., triplets, since the number of features increases exponentially with the order. We propose an algorithm for identifying high-order spatial features efficiently. The algorithm directly evaluates the inner product of the feature vectors from two images to be compared, identifying all high-order features auto- matically. The algorithm hence serves as a kernel for any kernel-based learning algorithms. The algorithm is based on the idea that if a high-order spatial feature co-occurs in both images, the occurrence of the feature in one image would be a translation from the occurrence of the same feature in the other image. This enables us to compute the kernel in time that is linear to the number of local features in an image (same as the bag of local features approach), regardless of the order. Therefore, our algorithm does not limit the upper bound of the order as in previous work.
We have developped variantions of the algorithm to applications including object recognition, object detection and local patch classification. We have also proposed algorithms based on this idea for both supervised learning and weakly supervised learning (only image level labels are given).
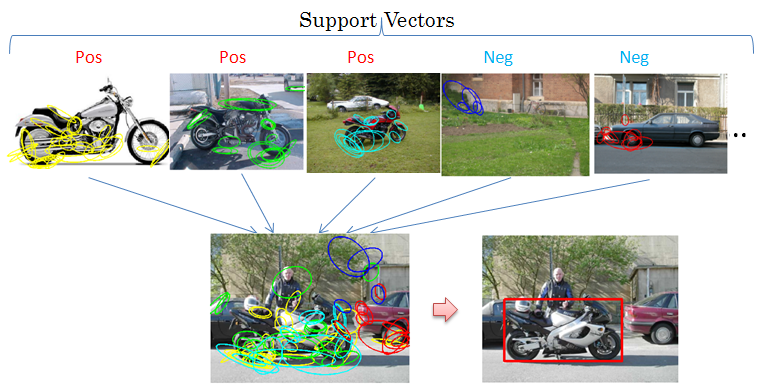
Discriminative Hough Transform for Object Detection
In this work, we develop a discriminative Hough transform model for fast object detection. The Hough transform provides an efficient way to detect objects. Various methods have been proposed to achieve discriminative learning of the Hough transform, but they have usually focused on learning discriminative weights to the local features, which reflect whether the features are matched on the object or the background. In this paper, we propose a novel approach to put the {\it whole} Hough transform into a maximum margin framework, including both the weights for the local features and their locations. This is achieved through the kernel methods of the SVM. We propose a kernel that can be used to learn a SVM classifier that determines the presence of the object in a subimage. The kernel is designed such that during testing, the standard Hough transform process can be used to obtain the exact decision scores of the SVM at every location and scale of a test image. The experiment results show that our approach significantly improves the detection performance over previous methods of learning the Hough transform.
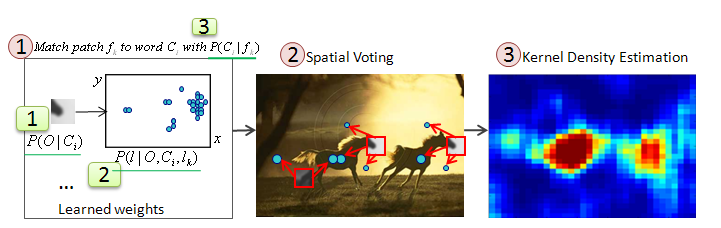
Improving Color Categorization with Shapes
In this work, we explore the problem of object color categorization from natural images. Previous works use the histograms of RGB values of images with learning base methods. We propose to use shape information to help to localize the foreground areas of an image that determine the color of the object (such as car hoods), and focus the color learning and prediction on these areas. A novel Co-PLSA model is proposed to jointly learn the color and shape detectors in weakly supervised manner, where training images are only labeled with the color categories, while the locations of the foreground areas are not provided.
The following figure illustrates the improvement of the foreground prediction (brighter part) as we iterate on the Co-PLSA model.

Old Project
Activity Graph for Intrusion Alert Analysis
Current Intrusion Detection Systems (IDSs) generate an unmanageable amount of alerts every day, and up to 99\% of these alerts are false alerts. As a result, it is difficult for human users to understand the alerts and take appropriate actions. In this paper, we will provide a number of techniques based on activity graphs to address this issue. To help manage the large amount of alerts, we aggregate raw alerts into scenarios using alert correlation techniques, and build activity graphs from each scenario. Thus we provide the user these activity graphs that indicate the activities that had taken place in the specific systems, instead of the unmanageable amount of raw alerts. In order to reduce false alerts, we classify the activity graphs into true attack strategies and normal scenarios. We present a system implementing the proposed algorithms with a graphical user interface. We do experiments with this system on Darpa 1999, 2000 and a real world datasets.
The following figure shows a screenshot of our system built with Java and PHP.