Amir Sadovnik
Research Interests
- Biologically Motivated Vision Models
- Object Recognition
- Machine Learning
- Image Descriptions
- Natural Language Processing
Current Research
Reffering Expression Generation for Visual Data
Publications:
A. Sadovnik, Y. Chiu, N. Snavely, S. Edelman and T. Chen. "Image Description with a Goal: Building Efficient Discriminating Expressions for Images", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
A. Sadovnik, A. Gallagher and T. Chen ."It's Not Polite To Point: Describing People With Uncertain Attributes.", Computer Vision and Pattern Recognition (CVPR), 2013.
A. Sadovnik, A. Gallagher and T. Chen ."Not Everybody's Special: Using Neighbors in Referring Expressions with Uncertain Attributes.", The V&L Net Workshop on Language for Vision, Computer Vision and Pattern Recognition (CVPR), 2013.
Referring expressions, which are sentences that try to refer to a single object within a group, have been studied extensively in the natural language processing (NLP) community. They are considered a basic building block for any natural language generation system. However, trying to generate these expressions for visual data, requires taking many other factors into effect which are not present when looking only at lists of objects and attributes (as is commonly done in the NLP community). These include uniquely visual factors such as visual saliency, classifier uncertainty, spatial arrangements, etc. My research tries to address these issues by developing algorithms which take them into consideration, and use human experiments to measure their efficiency.

Fig 1. Two examples of our algorithm constructing referring expressions for the people marked with the red rectangles in the images.
A Visual Dictionary Attack on Picture Passwords
A. Sadovnik and T. Chen, "A Visual Dictionary Attack on Picture Passwords.", IEEE International Conference on Image Processing (ICIP) 2013.
Amir Sadovnik, Tsuhan Chen
Microsoft's Picture Password provides a method to authenticate a user without the need of typing a character based password. The password consists of a set of gestures drawn on an image. The position, direction and order of these gestures constitute the password. Besides being more convenient to use on touch screen devices, this authentication method promises improved memorability in addition to improving the password strength against guessing attacks. However, how unpredictable is the picture password? In this paper we exploit the fact that different users are drawn to similar image regions, and therefore these passwords are vulnerable to guessing attacks. More specifically, we show that for portrait pictures users are strongly drawn to use facial features as gesture locations. We collect a set of Picture Passwords and, using computer vision techniques, derive a list of password guesses in decreasing probability order. We show that guessing in this order we are able to improve the likelihood of cracking a password within a certain number of guesses. For example, if each guess takes 1 millisecond, it would take on the order of 1000 years to guess 25% of the passwords using a brute force method. However, using our ranked guess list we are able to guess 25% of the passwords in about 16 minutes.

Fig 1. An example of four picture passwords given by four different people over the same image. The password consists of a series of three gestures. These can be any combination of taps (blue), lines (red) and circles (green). The user is allowed to draw the gestures anywhere in the image. However, it is clear from the examples that users tend to choose similar locations. In this paper we use computer vision techniques to exploit this weakness, and measure how quickly a picture password can be guessed.
Previous Research
Hierarchical Object Groups for Scene Classification [publication]
Amir Sadovnik, Tsuhan Chen
The hierarchical structures that exist in natural scenes have been utilized for many tasks in computer vision. The basic idea is that instead of using strictly low level features it is possible to combine them into higher level hierarchical structures. These higher level structures provide a more specific feature and can thus lead to better results in classification or detection. Although most previous work has focused on hierarchical combinations of low level features, hierarchical structures exist on higher levels as well. In this work we attempt to automatically discover these higher level structures by finding meaningful object groups using the Minimum Description Length (MDL) principle. We then use these structures for scene classification and show that we can achieve a higher accuracy rate using them.
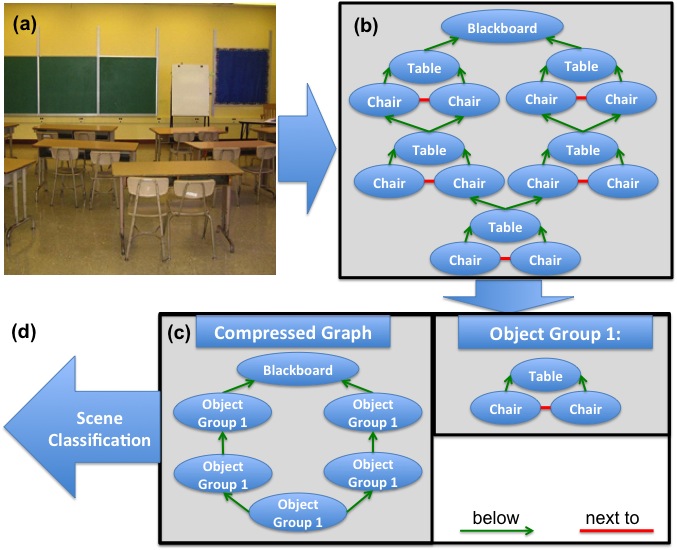
Fig 1. Given a labeled image (a) we can construct a graph which represents the different objects and their spatial relationships in the image (b). We then use the MDL principle to discover groups of objects which are able to compress the graph by replacing them with a single node (c). These object groups represent higher order concepts in the image, and therefore we predict they will be useful for different tasks. In this paper we show their usefulness for the task of scene classification (d).
Pictorial Structures for Object Recognition and Part Labeling in Drawing [project page] [publication]
Amir Sadovnik, Tsuhan Chen
Although the sketch recognition and computer vision communities attempt to solve similar problems in different domains, the sketch recognition community has not utilized many of the advancements made in computer vision algorithms. In this paper we propose using a pictorial structure model for object detection, and modify it to better perform in a drawing setting as opposed to photographs. By using this model we are able to detect a learned object in a general drawing, and correctly label its parts. We show our results on 4 categories.
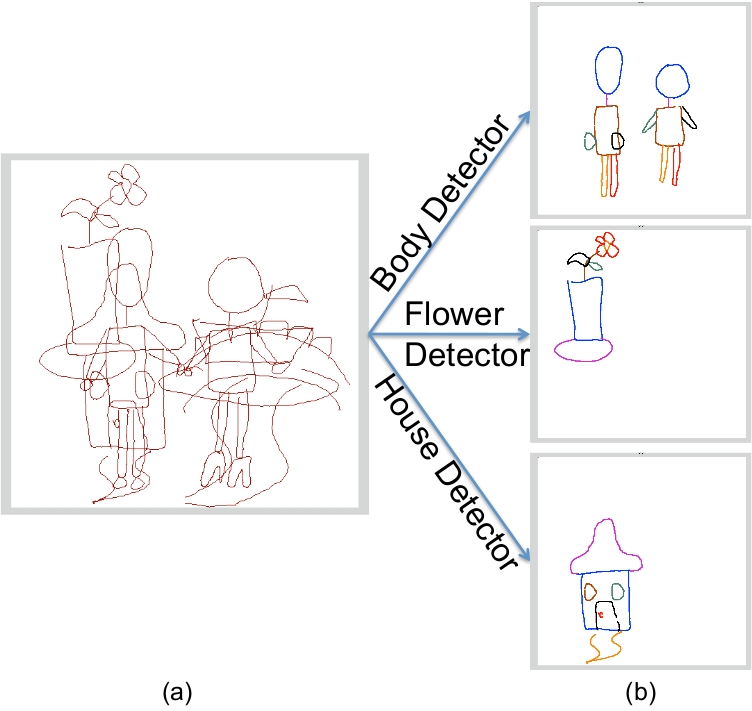
Fig 1. Example of the input (a) and output (b) of the algorithm. Note that
background strokes for each detector are successfully removed by our algorithm.