Congcong Li
Research Interests
- Computer vision
- Image/Video Analysis
- Machine Learning
- Human Cognition
Current Research
Discovering Groups of Objects for Scene Understanding
[Project page][Paper][Poster]
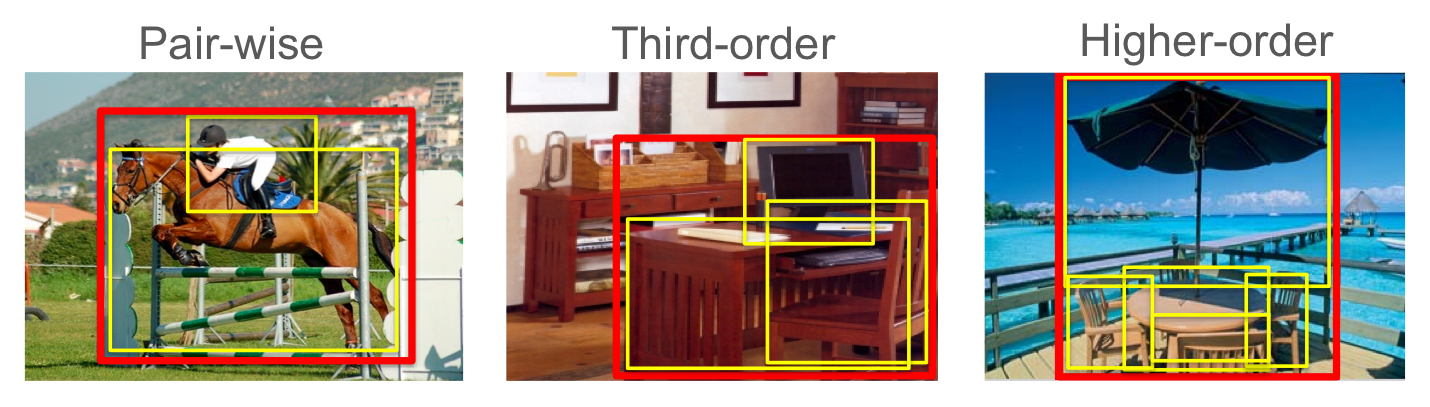
Objects in scenes interact with each other in complex ways. A key observation is that these interactions manifest themselves as predictable visual patterns in the image. Discovering and detecting these structured patterns is an important step towards deeper scene understanding. It goes beyond using either individual objects or the scene as a whole as the semantic unit. In this work, we promote ``groups of objects''. They are high-order composites of objects that demonstrate consistent spatial, scale, and viewpoint interactions with each other. These groups of objects are likely to correspond to a specific layout of the scene. They can thus provide cues for the scene category and can also prime the likely locations of other objects in the scene.
It is not feasible to manually generate a list of all possible groupings of objects we find in our visual world. Hence, we propose an algorithm that automatically discovers groups of arbitrary numbers of participating objects from a collection of images labeled with object categories. Our approach builds a 4-dimensional transform space of location, scale and viewpoint, and efficiently identifies all recurring compositions of objects across images. We then model the discovered groups of objects using the deformable parts-based model. Our experiments on a variety of datasets show that using groups of objects can significantly boost the performance of object detection and scene categorization.
Discovering Adaptive Contextual Cues
[Project page][Paper][Poster][Slides][Video]

Existing approaches to contextual reasoning for enhanced object detection typically utilize other labeled categories in the images to provide contextual information. As a consequence, they inadvertently commit to the granularity of information implicit in the labels. Moreover, large portions of the images may not belong to any of the manually-chosen categories, and these unlabeled regions are typically neglected. In this paper, we overcome both these drawbacks and propose a contextual cue that exploits unlabeled regions in images. Our approach adaptively determines the granularity (scene, inter-object, intra-object, etc.) at which contextual information is captured.
In order to extract the proposed contextual cue, we consider a scene to be a structured configuration of objects; just as an object is a composition of parts. We thus learn our proposed ``contextual meta-objects'' using any off-the-shelf object detector, which makes our proposed cue widely accessible to the community. Our results show that incorporating our proposed cue provides a relative improvement of 12% over a state-of-the-art object detector on the challenging PASCAL dataset.
Feedback Enabled Cascaded Classification Models
[Project page][Demo][Applications]
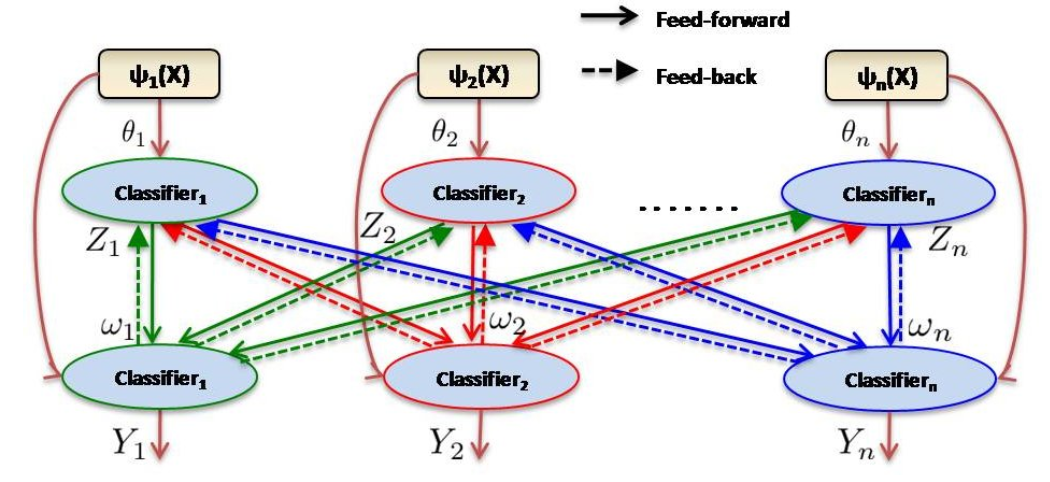
In many machine learning domains (such as scene understanding), several related sub-tasks (such as scene categorization, depth estimation, object detection) operate on the same raw data and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring to make any changes to the inner workings of any classifier. A recent method called Cascaded Classification Models (CCM) attempts to do so by repeated instantiations of the individual classifiers in a cascade; however, it is limited in that the learning algorithm does not maximize the joint likelihood of the sub-tasks, but rather learns only in a feed-forward way.
We propose Feed-back Enabled Cascaded Classification Models (FE-CCM), that maximizes the joint likelihood of the sub-tasks by using an iterative algorithm. A feedback step allows later classifiers to provide earlier stages information about what error modes to focus on. We have shown that our method significantly improves performance in all the sub-tasks in two different domains: scene understanding and robotic grasping.
Context-embedded Parameter Learning for Scene Understanding
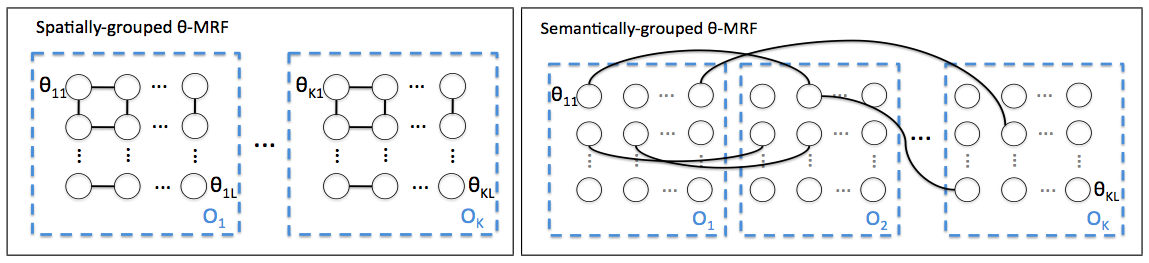
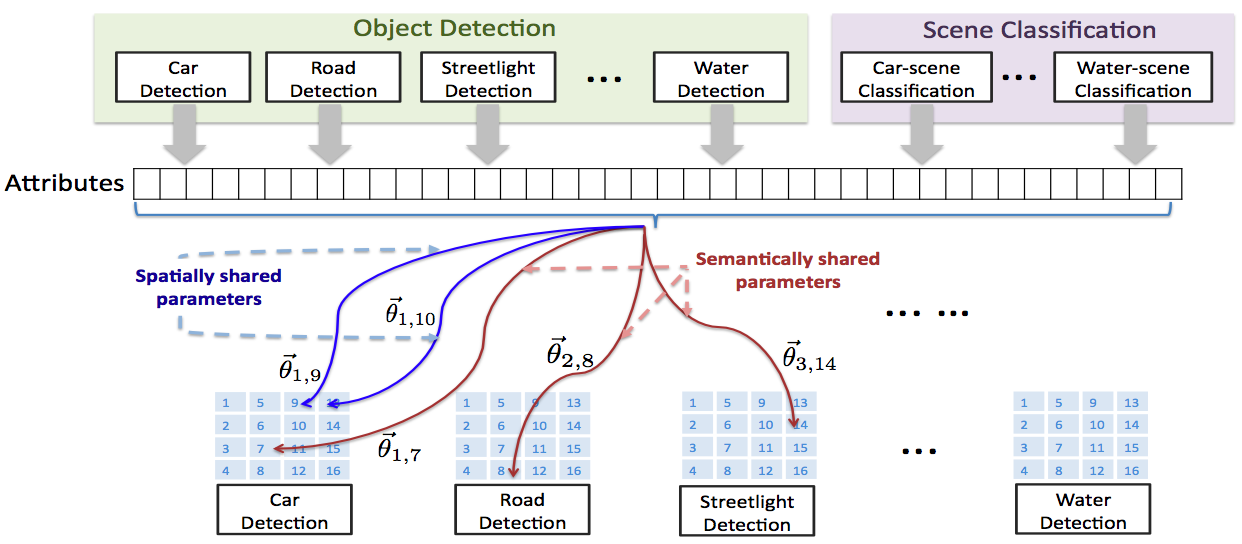
For most scene understanding tasks (such as object detection or depth estimation), the classifiers need to consider contextual information in addition to the local features. We can capture such contextual information by taking as input the features/attributes from all the regions in the image. However, this contextual dependence also varies with the spatial location of the region of interest, and we therefore need a different set of parameters for each spatial location. This results in a very large number of parameters. In this work, we model the independence properties between the parameters for each location and for each task, by defining a Markov Random Field (MRF) over the parameters. In particular, two sets of parameters are encouraged to have similar values if they are spatially close or semantically close. Our method is, in principle, complementary to other ways of capturing context such as the ones that use a graphical model over the labels instead. In extensive evaluation over two different settings, of multi-class object detection and of multiple scene understanding tasks (scene categorization, depth estimation, geometric labeling), our method beats the state-of-the-art methods in all the four tasks.
Aesthetic quality Assessment and Optimization for Consumer Photos
[Project page] [Demo]

Aesthetic Visual Quality Assessment

The goal is to study the media visual quality in the sense of aesthetics. Current work focuses on a special type of visual media: digital images of paintings. We develop a machine learning scheme to explore the relationship between aesthetic perceptions of human and the computational visual features extracted from paintings. We are extending this work to different media, such as photo, graph arts, video, etc.
We design a group of methods to extract features to represent both the global characteristics and local characteristics of a painting. Inspiration for these features comes from our prior knowledge in art and a questionnaire survey we conducted to study factors that affect human’s judgments. We collect painting images and ask human subjects to score them. These paintings are then used for both training and testing in our experiments. Experiment results show that the proposed work can classify high-quality and low-quality paintings with performance comparable to human.
Motion-Focusing Video Summarization
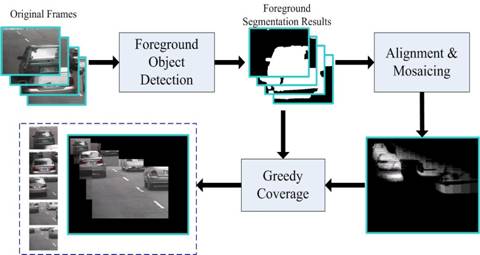
In this work, we propose a motion-focusing method to extract key frames and generate summarization synchronously for surveillance videos. Within each pre-segmented video shot, the proposed method focuses on one constant-speed motion and aligns the video frames by fixing this focused motion into a static situation. According to the relative motion theory, the other objects in the video are moving relatively to the selected kind of motion. This method finally generates a summary image containing all moving objects and embedded with spatial and motional information, together with key frames to provide details corresponding to the regions of interest in the summary image. We apply this method to the lane surveillance system and the results provide us a new way to understand the video efficiently.