Adarsh Kowdle
Research Interests
- Computer vision
- Machine learning
Primary Focus
- Interactive computer vision algorithms
- Image based modeling
Check out short videos about my research here
My research broadly falls into three categories,
- Image based modeling: The task of image based modeling refers to recovering 3D structure from 2D images. My work in this space predominantly revolves around putting the user in the loop with the algorithm in a discrete labeling framework. In one approach, the user initiates the algorithm by indicating the object of interest via scribbles that helps obtain the 3D model of the object of interest [ECCV '10, ICIP '11]. We have successfully extended this to an iOS application to achieve this task on a mobile device [Demo at CVPR '12]. In an alternate approach, I have explored an active learning framework where the algorithm initiates the process of 3D modeling and guides the user towards providing support cues to improve the 3D model [CVPR '11]. In extensions of image based modeling to videos, I have proposed an algorithm to temporally segment a video to clips of four classes - static vs. dynamic camera and static vs. dynamic scene revealing interesting trends in Hollywood movies across time [ECCV '12]. Using this segmentation as a pre-processing step, I have explored estimating the depth of the scene in hard scenarios where the scene has a dynamic object [ICIP '12, CVPR '13].
- Object co-segmentation: Segmenting out the common foreground object from a group of images is the task of co-segmentation. In initial work, we explored the task of interactive co-segmentation where the user provides cues to the algorithm indicating the foreground. We explored the importance of the user choosing the right image to provide interactions [ICIP '09], how can interactive segmentation help perform better image retrieval [CVPR '09], and how the algorithm can actively guide the user to provide useful cues [CVPR '10, IJCV '11, SpringerBriefs '11]. This can be extended to multiview co-segmentation [ECCV '10]. In addition, I have proposed an unsupervised algorithm to achieve the task using stereo and appearance cues [ECCV '12].
- Holistic scene understanding: We refer to the task of recovering various high level cues given an image, such as scene recognition, depth estimation, object detection, etc. as holistic scene understanding. In this domain we have proposed a new model called Feedback Enabled Cascaded Classifier Models (FECCM) to combine information from these different vision tasks into one framework to aide each other [TPAMI '12, NIPS '10, ECCV '10].
Some of my other research activities include advising masters and undergraduate students towards their respective thesis. A list of these projects are given below under mentored projects.
Current Research
Learning to Segment a Video to Clips Based on Scene and Camera Motion [Project page | pdf]
Adarsh Kowdle, Tsuhan Chen
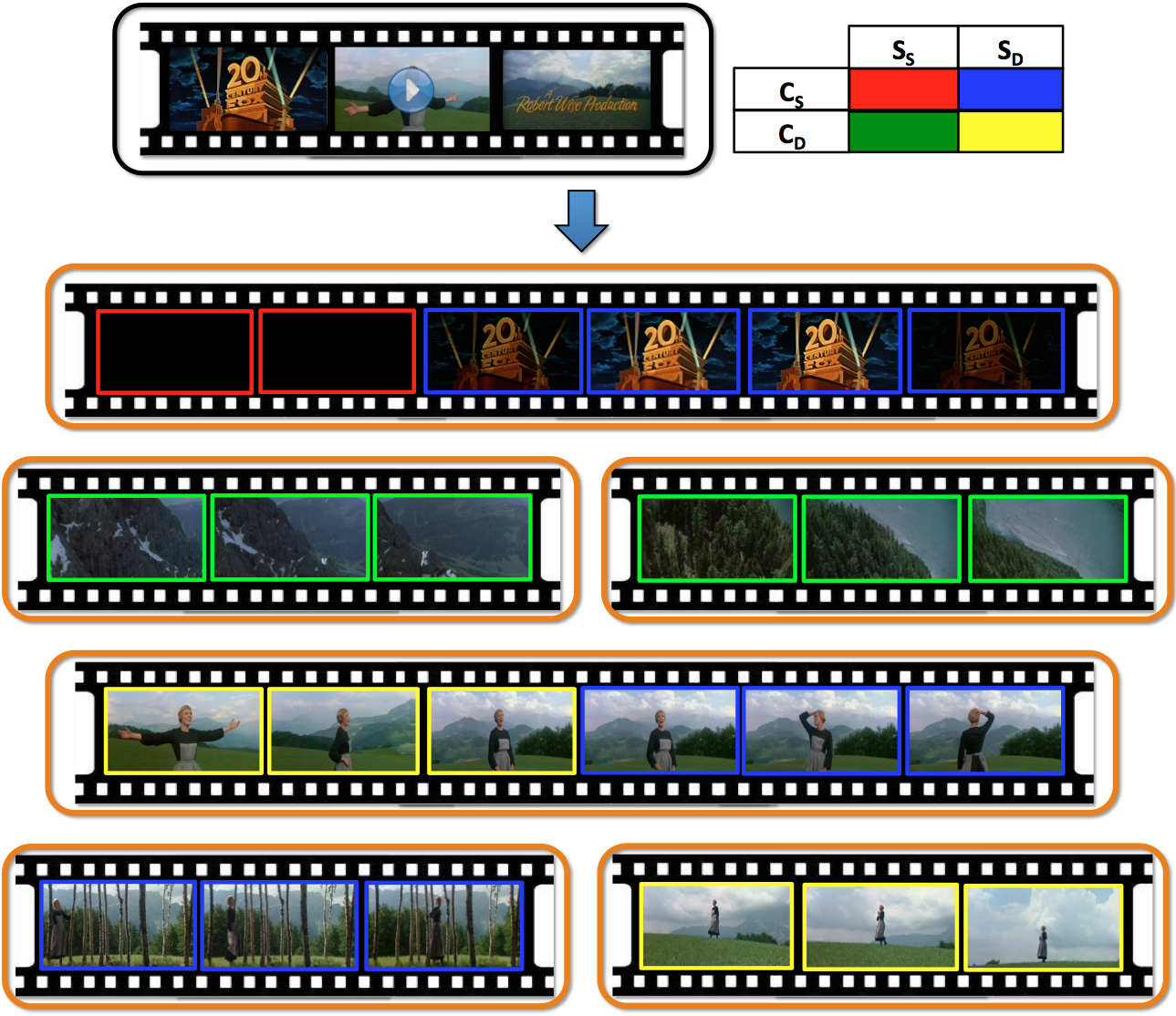
We present a novel learning-based algorithm for temporal segmentation of a video into clips based on both camera and scene motion, in particular, based on combinations of static vs. dynamic camera and static vs. dynamic scene. Given a video, we first perform shot boundary detection to segment the video to shots. We enforce temporal continuity by constructing a markov random field (MRF) over the frames of each video shot with edges between consecutive frames and cast the segmentation problem as a frame level discrete labeling problem. Using manually labeled data we learn classifiers exploiting cues from optical flow to provide evidence for the different labels, and infer the best labeling over the frames. We show the effectiveness of the approach using user videos and full-length movies. Using sixty full-length movies spanning 50 years, we show that the proposed algorithm of grouping frames purely based on motion cues can aid computational applications such as recovering depth from a video and also reveal interesting trends in movies, which finds itself interesting novel applications in video analysis (time-stamping archive movies) and film studies.
Multiple View Object Cosegmentation using Appearance and Stereo Cues [Project page | pdf | slides | videolecture]
Adarsh Kowdle, Sudipta Sinha, Richard Szeliski
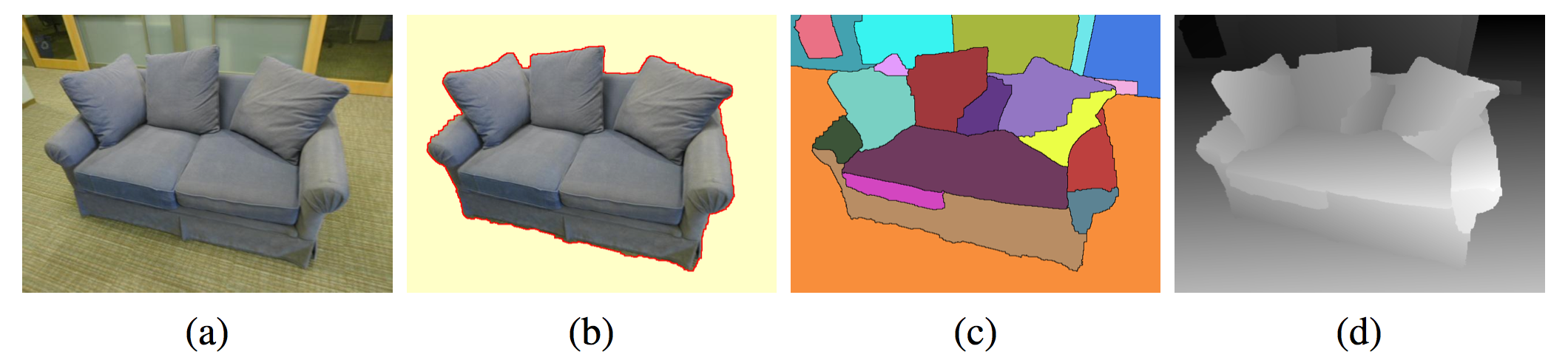
We present an automatic approach to segment an object in calibrated images acquired from multiple viewpoints. Our system starts with a new piecewise planar layerbased stereo algorithm that estimates a dense depth map that consists of a set of 3D planar surfaces. The algorithm is formulated using an energy minimization framework that combines stereo and appearance cues, where for each surface, an appearance model is learnt using an unsupervised approach. By treating the planar surfaces as structural elements of the scene and reasoning about their visibility in multiple views, we segment the object in each image independently. Finally, these segmentations are refined by probabilistically fusing information across multiple views. We demonstrate that our approach can segment challenging objects with complex shapes and topologies, which may have thin structures and non-Lambertian surfaces. It can also handle scenarios where the object and background color distributions overlap significantly.
Active Learning for Piecewise Planar 3D Reconstruction [Project page | pdf | slides]
Adarsh Kowdle, Yao-Jen Chang, Andrew Gallagher, Tsuhan Chen

In this work, we present an active-learning algorithm for piecewise planar 3D reconstruction of a scene. While previous interactive algorithms require the user to provide tedious interactions to identify all the planes in the scene, we build on successful ideas from the automatic algorithms and introduce the idea of active-learning, thereby improving the reconstructions while considerably reducing the effort.
Our algorithm first attempts to obtain a piecewise planar reconstruction of the scene automatically through an energy minimization framework. The proposed active-learning algorithm, then uses intuitive cues to quantify the uncertainty of the algorithm and suggest regions, querying the user to provide support for the uncertain regions via simple scribbles. These interactions are used to suitably update the algorithm, leading to better reconstructions. We show through machine experiments and a user study that the proposed approach can intelligently query the users for interactions in informative regions, and users following these can achieve better reconstructions of the scene and faster, especially in case of textureless surfaces and scenes lacking cues like lines which the automatic algorithms rely on.
Scribble Based Interactive 3D Reconstruction via Scene Cosegmentation [Project page | pdf]
Adarsh Kowdle, Yao-Jen Chang, Dhruv Batra, Tsuhan Chen
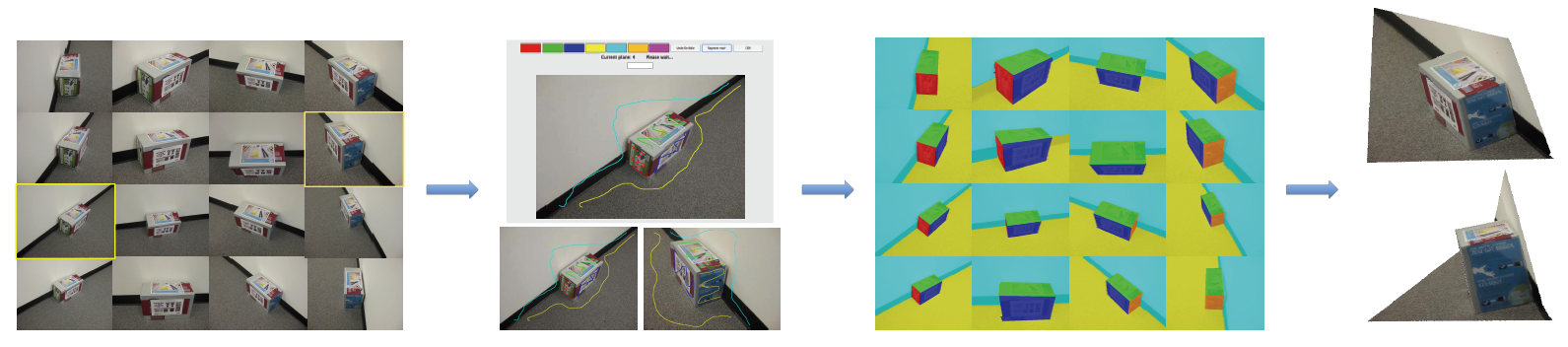
In this work, we present a novel interactive 3D reconstruction algorithm which renders a planar reconstruction of the scene. We consider a scenario where the user has taken a few images of a scene from multiple poses. The goal is to obtain a dense and visually pleasing reconstruction of the scene, including non-planar objects. Using simple user interactions in the form of scribbles indicating the surfaces in the scene, we develop an idea of 3D scribbles to propagate scene geometry across multiple views and perform co-segmentation of all the images into the different surfaces and the non-planar objects in the scene. We show that this allows us to render a complete and pleasing planar reconstruction of the scene along with a volumetric rendering of the non-planar objects. We demonstrate the effectiveness of our algorithm on both outdoor and indoor scenes including the ability to handle featureless surfaces.
iModel: Interactive Co-segmentation for Object of Interest 3D Modeling [Project page | pdf]
Adarsh Kowdle, Dhruv Batra, Wen-Chao Chen, Tsuhan Chen
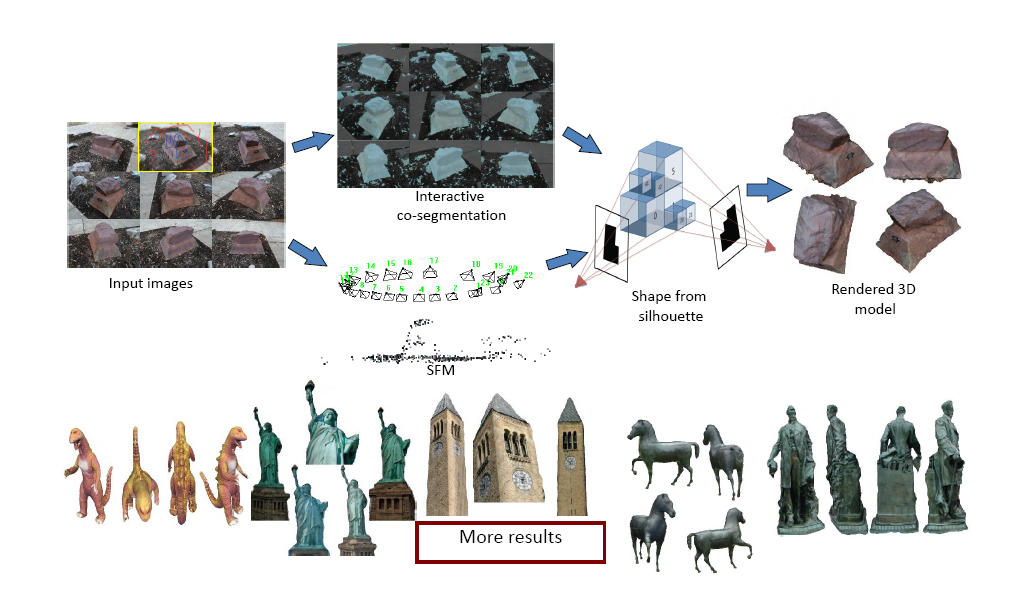
We present an interactive system to create 3D models of objects of interest in their natural cluttered environments. A typical setting for 3D modeling of an object of interest involves capturing images from multiple views in a multi-camera studio with a mono-color screen or structured lighting. This is a tedious process and cannot be applied to a variety of objects. Moreover, general scene reconstruction algorithms fail to focus on the object of interest to the user.
In this work, we use successful ideas from the object cut-out literature, and develop an interactive-cosegmentation-based algorithm that uses scribbles from the user indicating foreground (object to be modeled) and background (clutter) to extract silhouettes of the object of interest from multiple views. Using these silhouettes, and the camera parameters obtained from structure-from-motion, in conjunction with a shape-from-silhouette algorithm we generate a texture-mapped 3D model of the object of interest.
iCoseg: Interactive cosegmentation by touch [Project page]
Dhruv Batra, Adarsh Kowdle, Devi Parikh, Kevin Tang,Yu-Wei Chao, Jiebo Luo, Tsuhan Chen
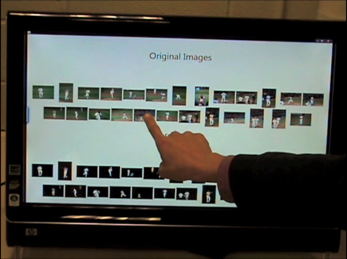


The advent of commercial touch-screen devices, like the HP Touchsmart™, the Microsoft Surface™ or the Apple iPhone™, has opened new avenues for human-computer interactions. In this demo, we present one such interactive application - Interactive Cosegmentation of a group of related images. We develop a user-friendly system on the HP Touchsmart™, which enables a user to cut out objects of interest from a collection of images by providing scribbles on a few images.
We present an algorithm for Interactive Cosegmentation of a foreground object from a group of related images. While previous approaches focus on unsupervised co-segmentation, we use successful ideas from the objectcutout literature. We develop an algorithm that allows users to decide what foreground is, and then guide the output of the co-segmentation algorithm towards it via scribbles. Interestingly, keeping a user in the loop leads to simpler and highly parallelizable energy functions, allowing us to work with significantly more images per group. However, unlike the interactive single image counterpart, a user can not be expected to exhaustively examine all (tens of) cutouts returned by the system to make corrections. Hence, we propose iCoseg, an automatic recommendation system that intelligently recommends where the user should scribble next. We introduce and make publicly available the largest cosegmentation dataset with 38 groups, 643 images, and pixelwise groundtruth annotations. Through machine experiments and real user studies with our developed interface, we show that iCoseg can intelligently recommend regions to scribble on, and users following these recommendations can achieve good quality cutouts with significantly lower time and effort than exhaustively examining all cutouts.
Feedback Enabled Cascaded Classification Models
(Holistic Scene Understanding) [Project page | pdf | supplementary | extended version]
Joint work with Congcong Li and Ashutosh Saxena
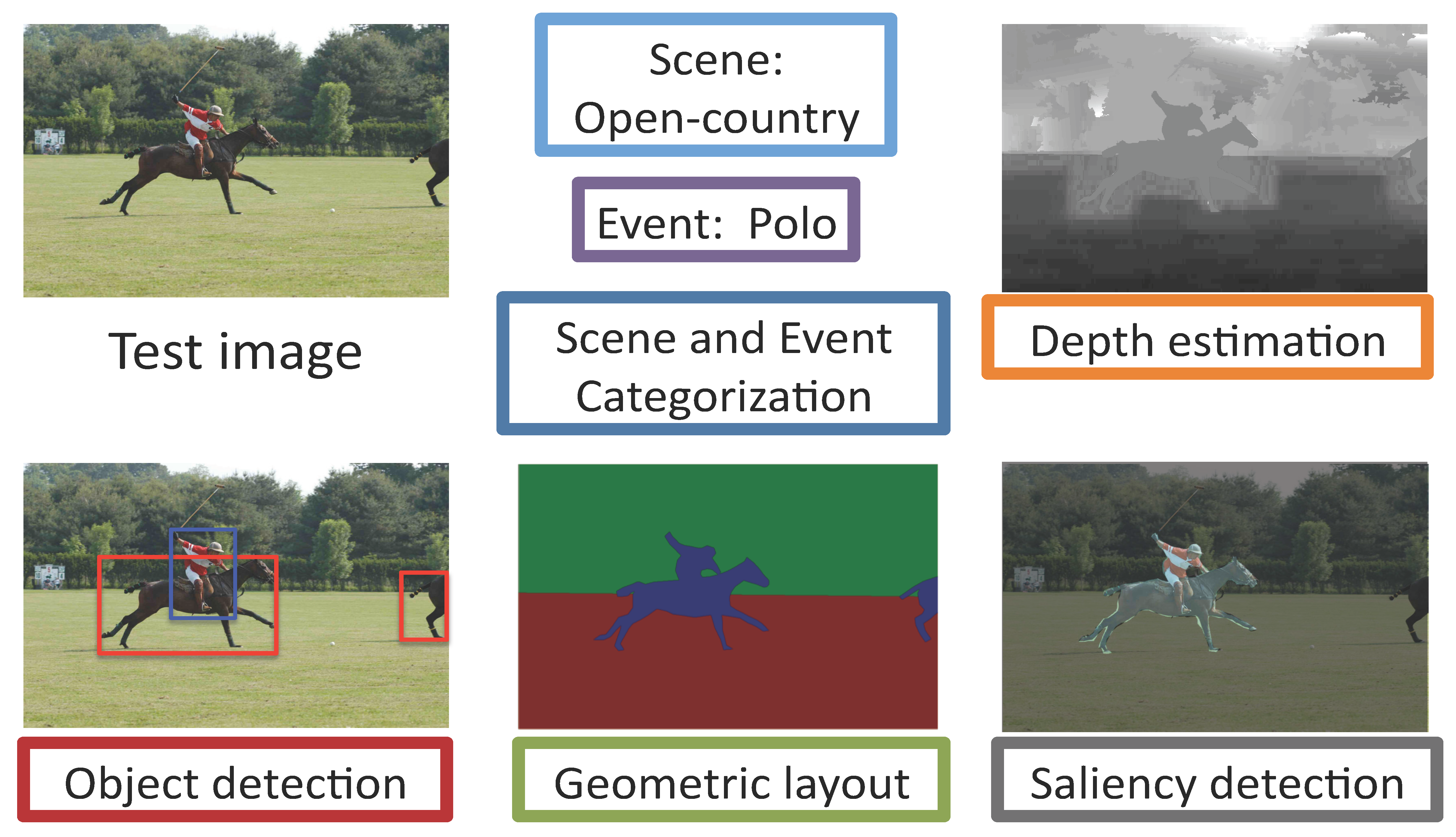
In many machine learning domains (such as scene understanding), several related sub-tasks (such as scene categorization, depth estimation, object detection) operate on the same raw data and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring to make any changes to the inner workings of any classifier. A recent method called Cascaded Classification Models (CCM) attempts to do so by repeated instantiations of the individual classifiers in a cascade; however, it is limited in that the learning algorithm does not maximize the joint likelihood of the sub-tasks, but rather learns only in a feed-forward way.
We propose Feed-back Enabled Cascaded Classification Models (FE-CCM), that maximizes the joint likelihood of the sub-tasks by using an iterative algorithm. A feedback step allows later classifiers to provide earlier stages information about what error modes to focus on. We have shown that our method significantly improves performance in all the sub-tasks in two different domains: scene understanding and robotic grasping.
Past Research Projects
1. Online structured learning for Obstacle avoidance [Research report] [Slides]
Adarsh Kowdle, Zhaoyin Jia
2. Brain MRI classification using an Expectation Maximization algorithm [Research report]
Adarsh Kowdle, Kamil Bojanczyk
3. Parallel implementation of RANdom SAmple Consensus using OpenMP [slides]
4. Background subtraction and foreground classification for outdoor surveillance video [slides]
Adarsh Kowdle, Mukta Gore, Utsav Prabhu
5. Structure and Motion recovery using Visual SLAM [Research report]
Adarsh Kowdle, Yao-Jen Chang, Tsuhan Chen

6. Implementation of a voice-based biometric system [Research report]
Adarsh K.P, A. R. Deepak, Diwakar. R, Karthik. R
Mentored Research Projects
1. Image based room schedule retrieval system - Shuai Yuan (2012) [Report]
2. iModel: Object of Interest 3D Modeling on a Mobile Device - Shaoyou Hsu, Haochen Liu (2012) [Report]
3. Sketch2Image Search - Sukhada Pendse, Xiaochen He (2012) [Report]
4. Comparitive study of 2D to 3D video conversion algorithms for static scenes and horizontal camera motion - Ling-Wei Lee (2011) [Report]
5. 3D interactive interface using a kinect sensor - Anandram Sundar (2011) [Report]
6. Conversion of 2D videos of dynamic scene captured from a static camera to 3D videos - Anandram Sundar (CS6780 course project, 2011) [Report]
7. Local Color Pattern features for interactive co-segmentation - Andrew Mui (2010) [Report]
8. Object of interest discovery in video sequences - Liang-Tin Kuo, Bindu Pan (2010) [Report]
9. iCoseg: iPhone application to perform interactive cosegmentation - Jason Lew (2010) [Report]
10. iScribble: Java based user interface - Kevin Tang (2009) [Download]